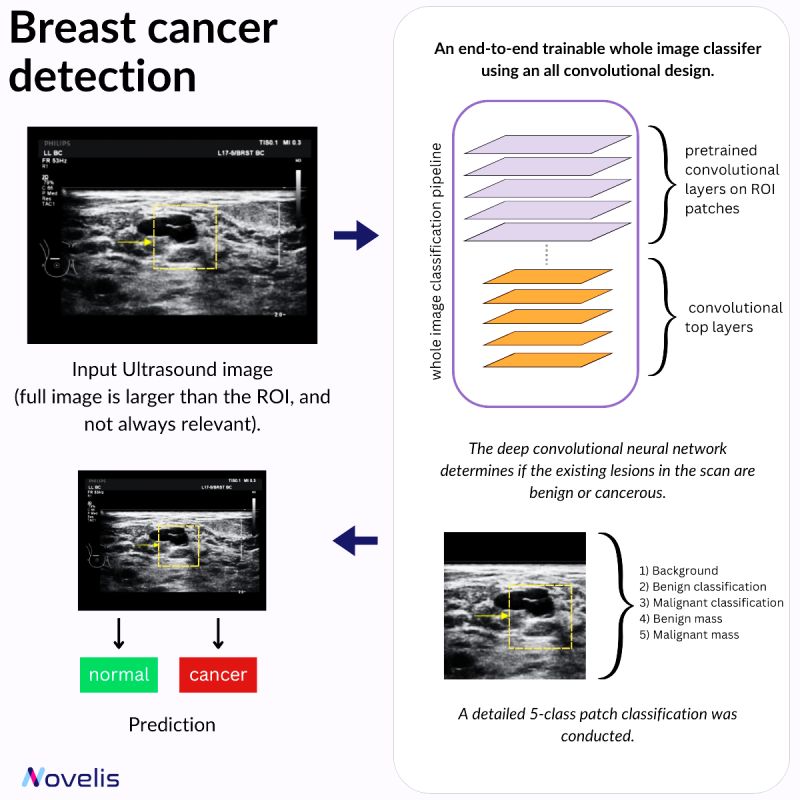
Deep Learning to Improve Breast Cancer Detection on Screening Mammography
Our focus this month is on how AI can be used in healthcare. This post will present a paper titled “Deep Learning to Improve Breast Cancer Detection on Screening Mammography” that covers an innovative deep-learning approach that aims to enhance breast cancer detection in screening mammography. A full-field digital mammography (FFDM) image typically has a resolution of 4000 x 3000 pixels, while a potentially cancerous region of interest (ROI) can be as small as 100 × 100 pixels. The method leverages these clinical ROI annotations to refine mammogram classification, which holds promise for significantly improving screening accuracy.
The technology utilizes an “end-to-end” training approach. It is trained on local image patches with detailed annotations and then adapts to whole images, requiring only image-level labels. This approach reduces dependence on detailed annotations, making it more versatile and scalable across various mammography databases.
Why is this essential? This paper is significant due to its potential to improve the accuracy of breast cancer detection in mammograms. It offers a more generalizable and scalable solution compared to traditional methods, reducing the risk of false positives and negatives. This approach could play a crucial role in early breast cancer detection and, therefore, help save lives by identifying cancer at more treatable stages.
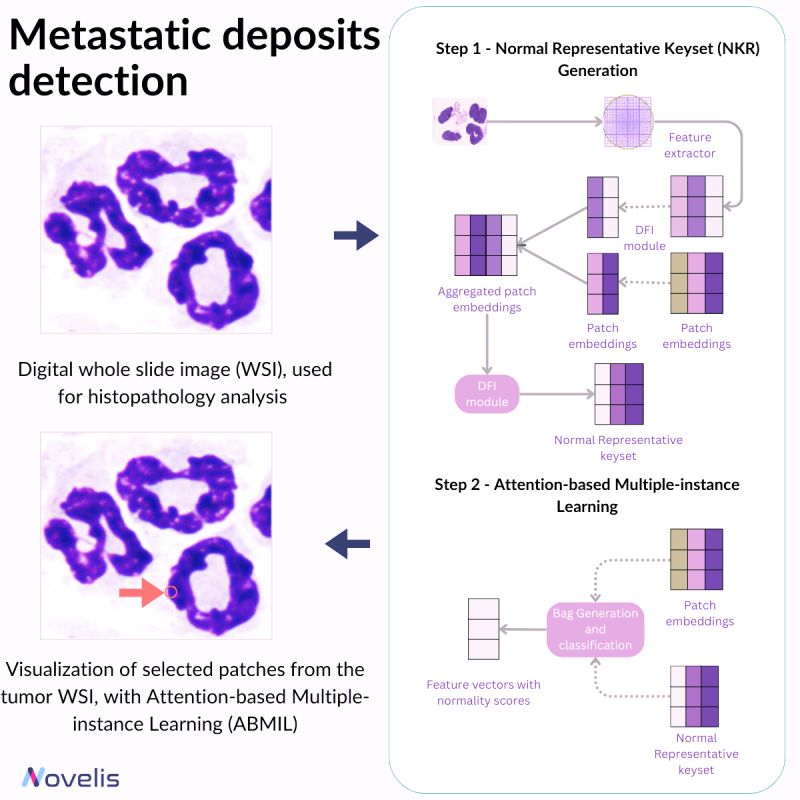
Metastatic deposits detection
Revolutionizing Cancer Diagnosis: The Vital Role of AI in Early Detection
Recent advancements in AI have significantly contributed to cancer research, particularly in analyzing histopathological imaging data. This reduces the need for extensive human intervention. In breast cancer, early detection of lymph node metastasis holds paramount importance, especially in the case of smaller tumors. Early diagnosis plays a crucial role in determining the treatment outcome. Pathologists often face difficulties in identifying tiny or subtle metastatic deposits, which leads to greater reliance on cytokeratin stains for improved detection. However, this method has inherent limitations and can be improved upon. This is where deep learning comes in as a vital alternative to address the intricacies of detecting small tumors early.
A notable approach within deep learning is the normal representative keyset attention-based multiple-instance learning (NRK-ABMIL). This technique consists of fine-tuning the attention mechanism to prioritize the detection of lesions. To achieve it, NRK-ABMIL establishes an optimal keyset of normal patch embeddings, referred to as the normal representative keyset.
Why is this essential? It is important to continue the research in whole slide images (WSIs) methods, with a particular emphasis on enhancing the detection of small lesions more precisely and accurately. This pursuit is crucial because advancing our understanding and refinement of WSIs can significantly impact early diagnosis and treatment efficacy.
Have you ever had a lengthy conversation with a chatbot (such as ChatGPT), only to realize that it has lost track of previous discussions or is no longer fluent? Or you’ve faced a situation where the input limit has been exhausted when using language model providers’ APIs. The main challenge with large language models (LLMs) is the context length limitation, which prevents us from having prolonged interactions with them and utilizing their full potential.
Researchers from the Massachusetts Institute of Technology, Meta AI, and Carnegie Mellon University have released a paper titled “Efficient Streaming Language Models With Attention Sinks”. The paper introduces a new technique for increasing the input lengths of LLMs without any loss in efficiency or performance degradation, all without model retraining.
The StreamingLLM framework stores the initial four tokens (called “sinks”) in a KV Cache as an “Attention Sink” on the already pre-trained models like LLaMA, Mistral, Falcon, etc. These crucial tokens effectively address the performance challenges associated with conventional “Window Attention” in LLMs, allowing them to extend their capabilities beyond their original input length and cache size limits. Using the StreamingLLM framework can help reduce both the perplexity (which measures how well a model predicts the next word based on context) and the computational complexity of the model.
Why is this important? This technique expands current LLMs to model sequences of over 4 million tokens without retraining while minimizing latency and memory footprint compared to previous methods.
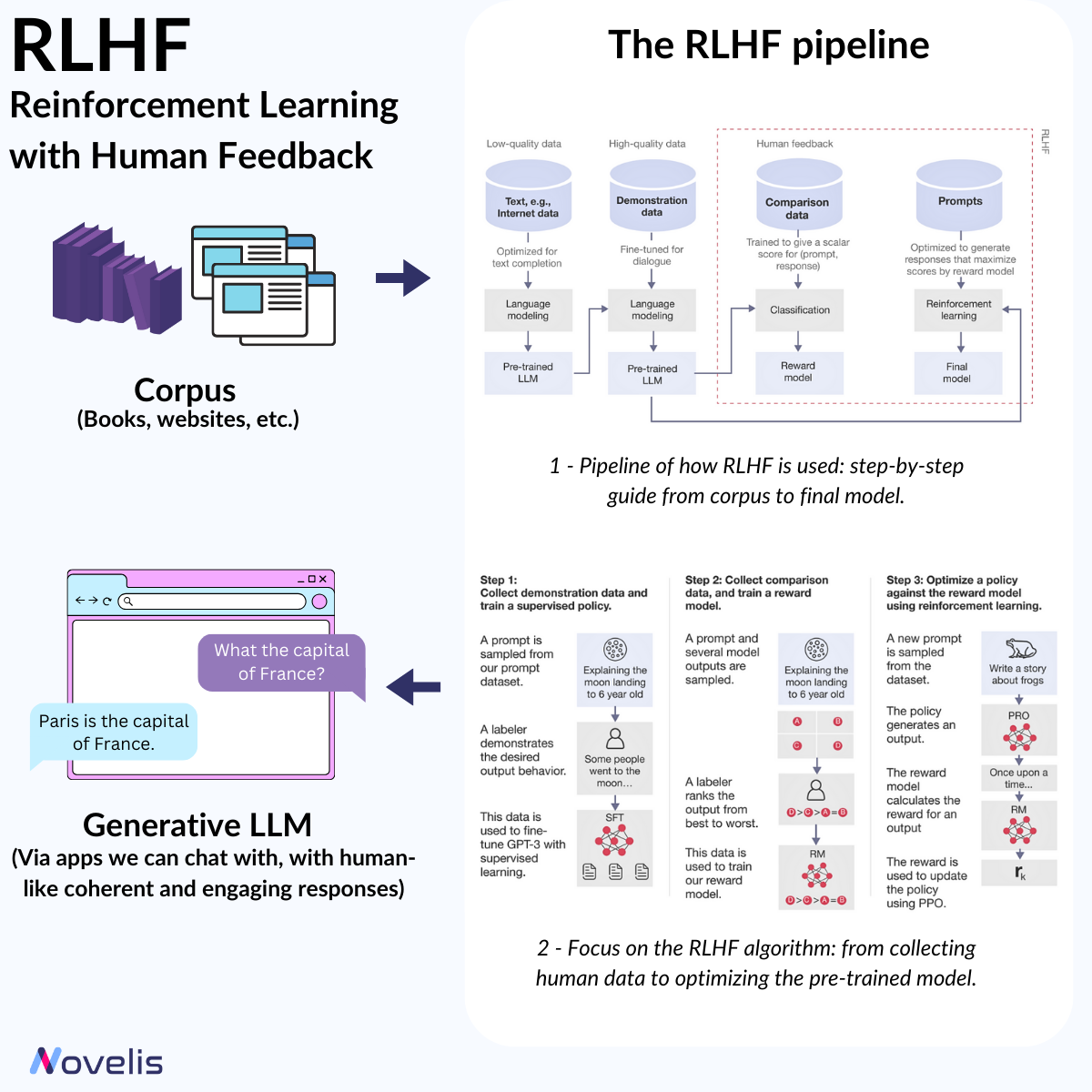
RLHF : adapt AI models with human input
Unlocking the Power of Reinforcement Learning from Human Feedback for Natural Language Processing
Reinforcement Learning from Human Feedback (RLHF) is a significant breakthrough in Natural Language Processing (NLP). It allows machine learning models to be refined using human intuition, leading to more contextually aware AI systems. RLHF is a machine learning method that adapt AI models (here, LLMs) using human input. The process involves creating a “reward model” based on human feedback, which is then used to optimize the behavior of an AI agent through reinforcement learning algorithms. Simply put, RLHF helps machines learn and improve by using the insights of human evaluators. For instance, an AI model can be trained to generate compelling summaries or engage in meaningful conversations using RLHF. The technique collects human feedback, often in the form of rankings or preferences, to create a reward model. This model helps the AI agent distinguish between good and bad outcomes and subsequently undergoes fine-tuning to align its behavior with the preferences identified in the human feedback. The result is more accurate, nuanced, and contextually appropriate responses.
OpenAI’s ChatGPT is a prime example of RLHF’s implementation in natural language processing applications.
Why is this essential? A clear understanding of RLHF is crucial to understanding the evolution of NLP and LLM and how they offer coherent, engaging, and easy-to-understand responses. RLHF helps AI models align with human values, providing answers that align with our preferences.
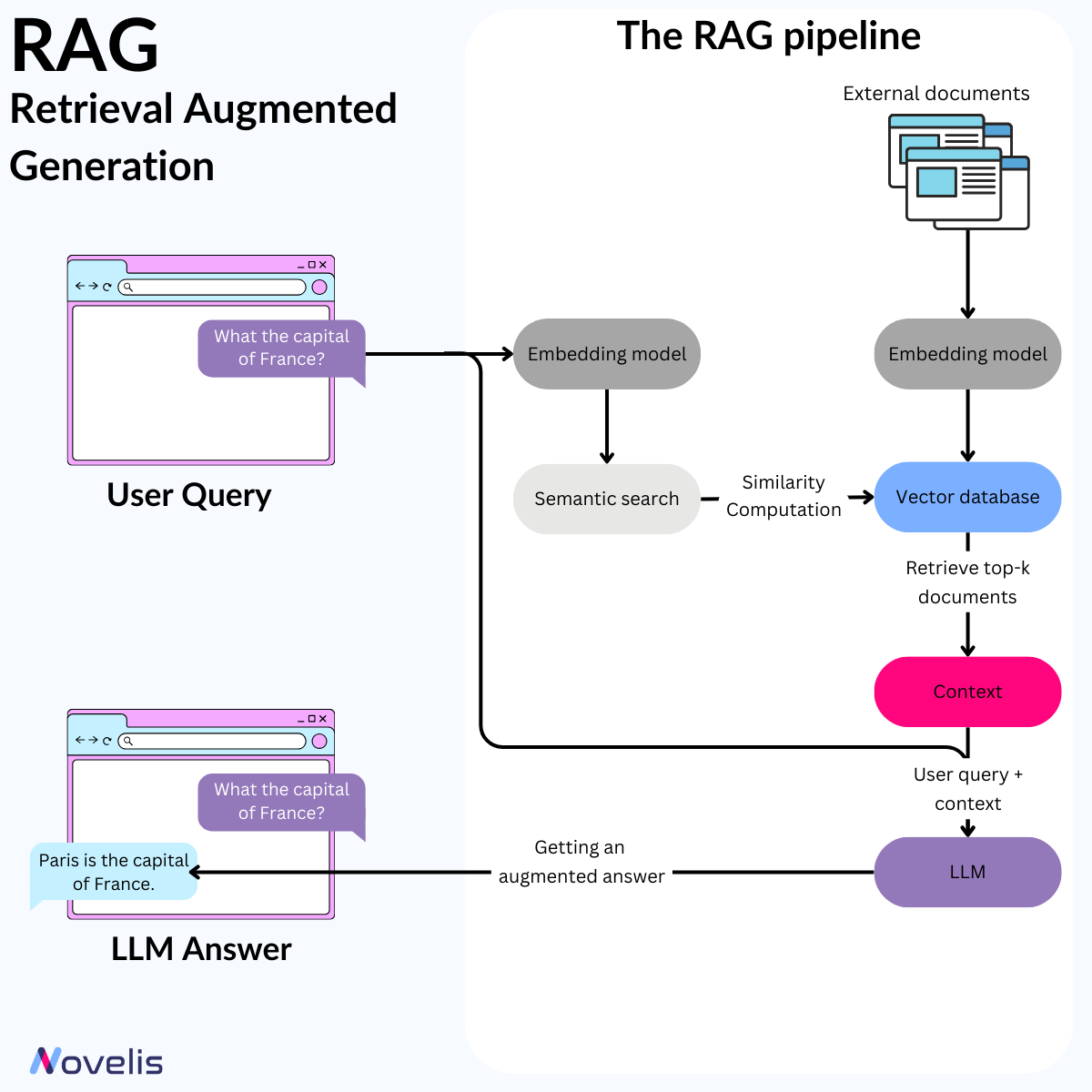
RAG : combine LLMs with external databases
The Surprisingly Simple Efficiency of Retrieval Augmented Generation (RAG)
Artificial intelligence is evolving rapidly, with large language models (LLMs) like GPT-4, Mistral, Llama, and Zephyr setting new standards. Although these models have improved interactions between humans and machines, they are still limited by existing knowledge. In September 2020, Meta AI introduced an AI framework called Retrieval Augmented Generation (RAG), which resolves some issues previously encountered by LMs and LLMs. RAG is designed to enhance the quality of responses generated by LLMs by incorporating external sources of knowledge and enriching the LLMs’ internal databases with accurate and up-to-date information. RAG is an AI system that combines LLMs with external databases to provide accurate and up-to-date answers to queries.
RAG has undergone continual refinement and integration with diverse language models, including the state-of-the-art GPT-4 and Llama 2.
Why is this essential? Reliance on potentially outdated data and a predisposition to generate inaccurate or misleading information are common issues faced by LLMs. However, RAG effectively addresses these problems by ensuring factual accuracy and consistency. It significantly mitigates the risks associated with data integrity breaches and dissemination of erroneous information. Moreover, RAG has displayed prowess across diverse benchmarks such as Natural Questions, WebQuestions, and CuratedTrec. This exemplifies its robustness and reliability. By integrating RAG, the need for frequent model retraining is reduced. This, in turn, reduces the computational and financial resources required to maintain LLMs.
CoT : design the best prompts to produce the best results
Chain-of-Thought: Can large language models reason?
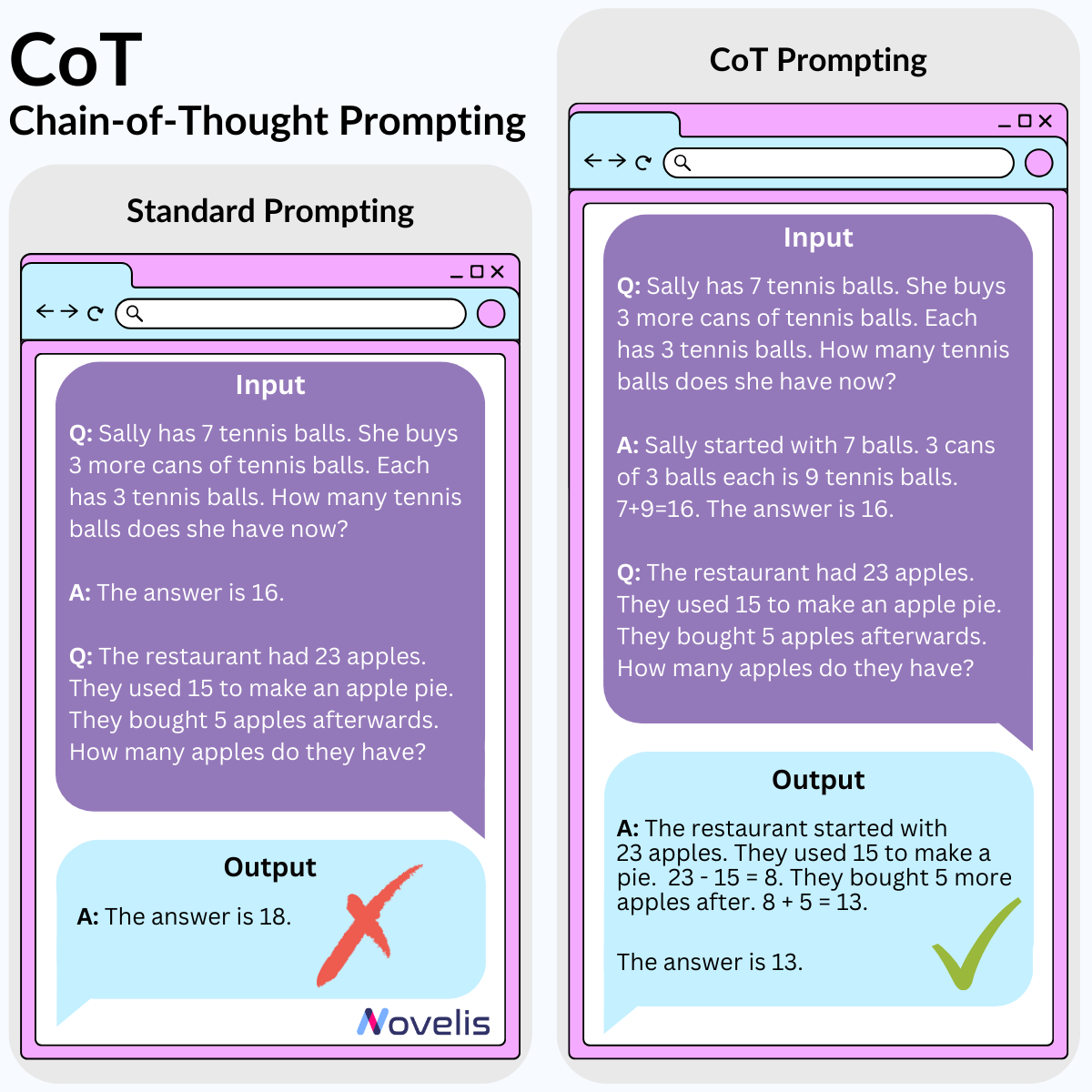
This month, we’ve been diving into the fascinating world of language modeling and generative AI. Today, we’ll be discussing on how to better use these LLMs. Ever heard of prompt engineering? This is the field of research dedicated to the design of better prompts in order for the large language model (LLM) you’re using to return the very best results. We’ll be introducing one such prompt engineering technique: Chain-of-Thought (CoT).
CoT prompting is a simple method that very closely resembles the way in which humans go about solving complex problems. If a problem seems a little long or a little too complex, we often tend to break that problem down into smaller sub-problems that we can more easily reason about. Well turns out this method works pretty well when replicated within (really) large language models (like GPT, BARD, PaLM, etc.). Give the model a couple examples of similar problems, explain how you’d handle them in plain language and that’s all! This works great for arithmetic problems, commonsense, and symbolic reasoning (aka good ol’ fashioned AI like rule-based problem solving).
Why is this essential? Applying CoT prompting has the potential to produce better results when handling arithmetic, commonsense, or rule-based problems when using your LLM of choice. It also helps to figure out where your LLM might be going wrong when trying to solve a problem (though the why of this question remains unknown). Try it out yourself! Now does this prove that our LLMs can really reason? That remains the million-dollar question.
Discover the linguistic modeling technologies, and LLMs in particular. In two informative articles, our team of experts shared with you the existing technologies.
LLM (large language model) : type of artificial intelligence program that can recognize and generate text.
Language Modelling and Generative AI
This month’s focus is on language modeling, an innovative AI technology that has emerged in the field of artificial intelligence, transforming industries, communication, and information retrieval. Using machine learning methods, language modeling creates language models (LMs) to help computers understand human language, and it powers virtual assistants and applications like ChatGPT. Let’s take a closer look at how it works.
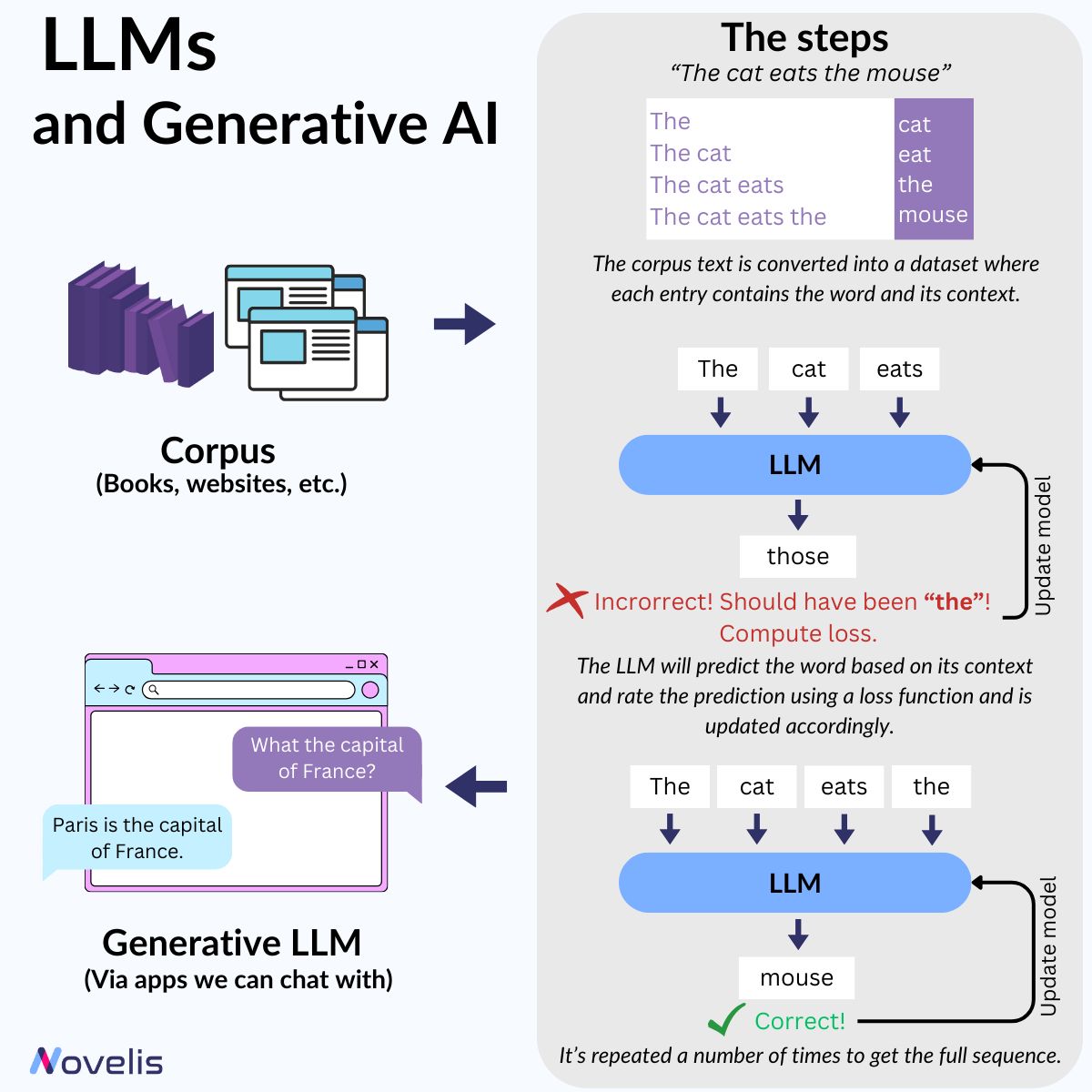
For computers to understand written language, LMs transform it into numerical representations. Current LMs analyze large text datasets, and, using statistical and probabilistic techniques, they use
the likelihood of a word appearing in a sentence to create the words’ vector representations. LMs are trained through pretraining tasks. Such a task could involve predicting a word based on its context
(i.e., its preceding or following words). In the sentences “X is a small feline” and “The X ate the mouse”, the model would have to figure out that the X refers to the word “cat”.
Once these representations are created, they can be used for different tasks and applications. One of these applications is language generation. The procedure for generating language using a language model is the following: 1) given the context, generate a probability distribution for the next token over all the tokens in the vocabulary; 2) pick the token with the highest probability; 3) add this token to the sequence, and repeat. A function that computes the performance loss of the model checks for correct responses and updates the model accordingly.
Why is this essential? All generative AI models, like ChatGPT, use these methods as the core foundation for their language generation abilities.
New models LLM models are being released every other day. Some of the most well-known models are the proprietary GPT (3.5 and 4) models, while others, such as LLaMa and Falcon, are open-source. Recently, Mistral released a new model made in France, showing promising results.
Optimization of large models : improve model efficiency, accuracy and speed
Unlocking LLM Potential: Optimizing Techniques for Seamless Corporate Deployment
Large Language Models (LLMs) have millions or billions of parameters. Consequently, deploying them for use in corporate tasks is a challenging task, given the limitation of resources within companies.
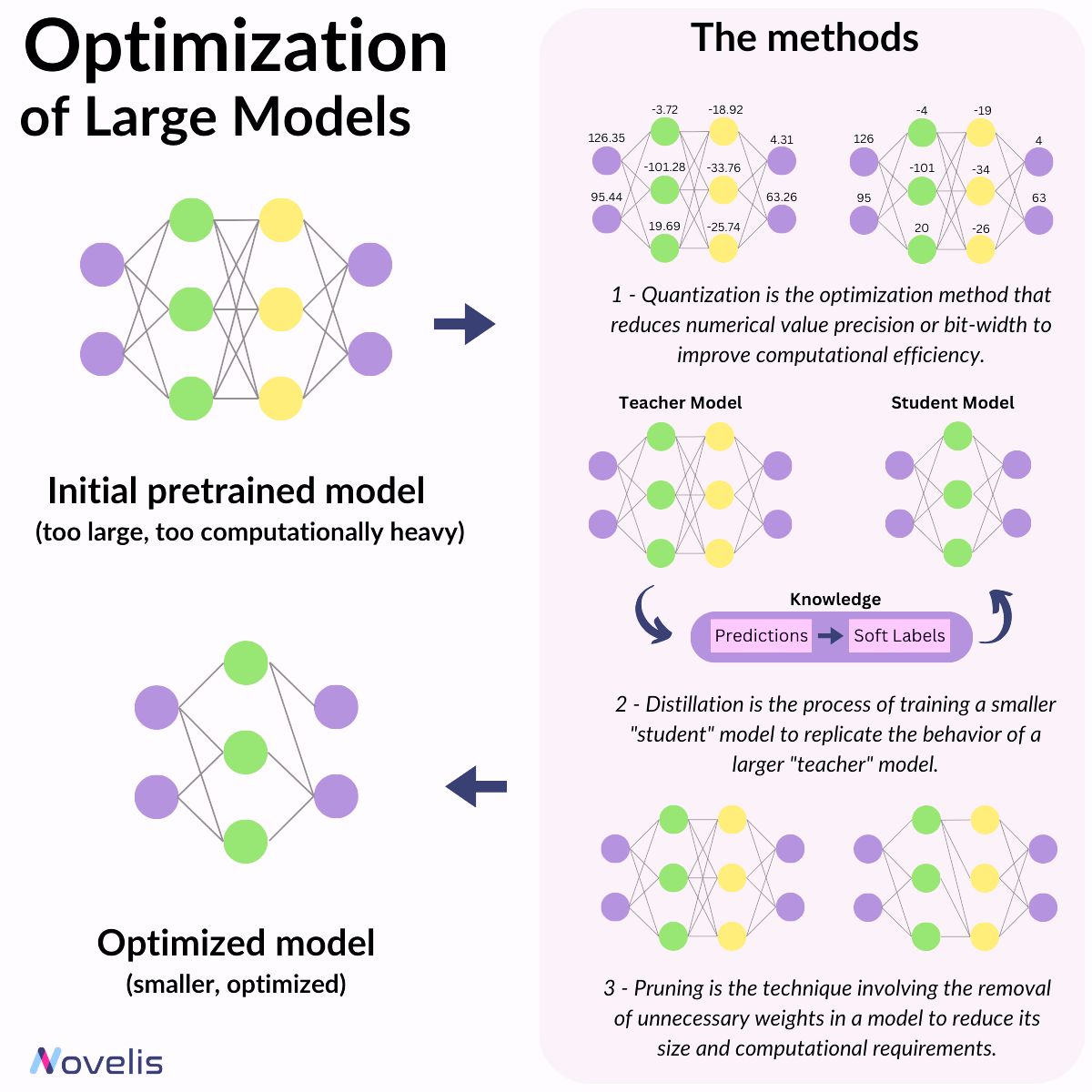
Therefore, researchers have been striving to achieve comparable or competitive performance from smaller models compared to their larger counterparts. Let’s take a look at these methods and how they can be used for optimizing the deployment of LLM in a corporate setting.
The initial method is called distillation. In distillation, we have two models: the student and the teacher. The student model is trained to replicate the statistical behavior of the teacher model, either focusing on the final predictions or the hidden layers of the model. The second approach, called quantization, involves reducing the precision or bit-width of numerical values, optimizing computational efficiency and memory usage. Lastly, pruning entails the removal of unnecessary or less critical connections, weights, or neurons to reduce the model’s size and computational requirements. The most well-known pruning technique is LoRA, a method crucial for achieving efficient and compact large language models.
Why is this essential? Leveraging smaller models to achieve comparable or superior performance compared to their larger counterparts offers a promising solution for companies striving to develop cutting-edge technology with limited resources.
On October 3rd, Novelis was present at AM Tech Day, the must-attend event for portfolio managers and asset managers organized by L’AGEFI.
During this event, Olivier Chosson, Director of Operations, discussed Novelis’ value proposition in an interview, focusing on how Novelis supports asset managers in optimizing asset management through generative AI, automation, and cybersecurity.
You can find the interview below:
Adrien: I’m pleased to welcome you to the AGEFI AM Tech Day studio today at the Palais Brongniart, Olivier Chosson. Hello!
Olivier: Hello, Adrien.
Adrien: You are an associate and director of operations at Novelis, and I naturally want to ask the question, Novelis, what is it?
Olivier: Novelis is a specialist in operational efficiency and supports its clients through the comprehensive analysis of their processes using tools such as Process Intelligence and Intelligent Automation. We also leverage Artificial Intelligence, including Generative AI, to enhance our offerings. We work on innovative architectures like modular architectures and, of course, cybersecurity to secure all the data we work with.
Our firm is structured around an R&D laboratory specializing in artificial intelligence. We exclusively employ AI researchers dedicated to fundamental research in this field, contributing to the advancement of models. Why did we take this initiative? To anticipate market developments and offer our clients and partners products as soon as they are mature and ready for operational use, ensuring their successful market deployment.
Adrien: So, you’ve really dived into the AI issue, fully embracing it.
Olivier: Indeed, that’s our job, and that’s what we’ve built the firm on for a little over 6 years now.
Adrien: I would have asked many people what they think about AI as a topic for the future. Some are addressing it today, but for others, it’s a topic for tomorrow. For you, it’s already a current issue, perhaps even since yesterday and today. So, in your opinion, what is the topic of tomorrow?
Olivier: For Novelis, Generative AI will become indispensable in the business world, starting from tomorrow. When we mention Generative AI, many people think of ChatGPT. However, starting today, companies have the opportunity to have their own ChatGPT model, specifically working on their data and processes.
What is the goal? It’s about delivering significant value, but for whom? Firstly, for their customers. Companies will be able to offer more personalized, faster, and higher-value services. This will also bring value to their employees. They can focus on their skills, develop their expertise, and provide even more value to customers. Ultimately, the entire company can increase its value in this way.
Adrien: And that’s what you do, you assist these companies in this process.
Olivier: Exactly. That’s our job.
Adrien: There you have it. For those who want to learn more, you can, of course, visit the Novelis booth here at the AM Tech Day.
Olivier: Exactly.
Adrien: Olivier Chosson, partner and director of operations at Novelis, thank you very much.
Discover 4 articles about Computer Vision conduct by our Research Lab Team
YOLO: A real-time object detection algorithm for multiple objects in an image in a single pass
YOLO: Simplifying Object Detection
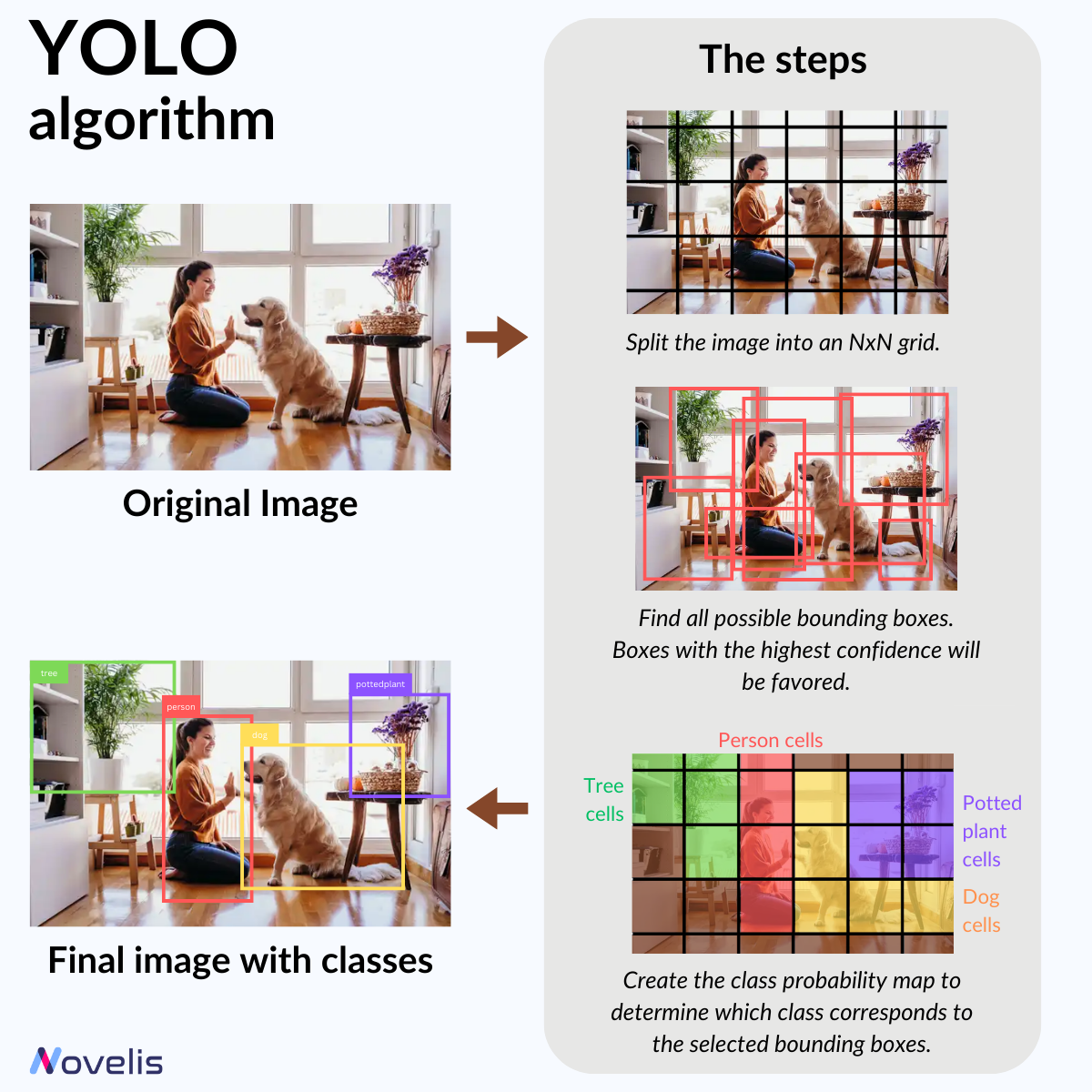
YOLO (You Only Look Once) is a state-of-the-art real-time object detection technique in computer vision. It uses a neural network for fast object detection. YOLO divides an image into bounding boxes to capture objects of different sizes. Then, it predicts each box’s object class (is it a dog? a cat? a plant?). How? By learning a class probability map to determine the object class associated with those boxes.
Think of YOLO this way: it works by capturing essential image features, refining them, and pinpointing potential object locations. It learns patterns to identify objects in input images through training on labeled examples. During the prediction process, it analyzes an image just once, quickly detects objects, and removes duplicates along the way.
The latest iteration of YOLO is the v8, by Ultralytics, but the v5 still holds its ground.
Why is this essential? It’s like teaching a computer to instantly spot things! YOLO excels in speed and accuracy, perfect for tasks like robotics or self-driving cars.
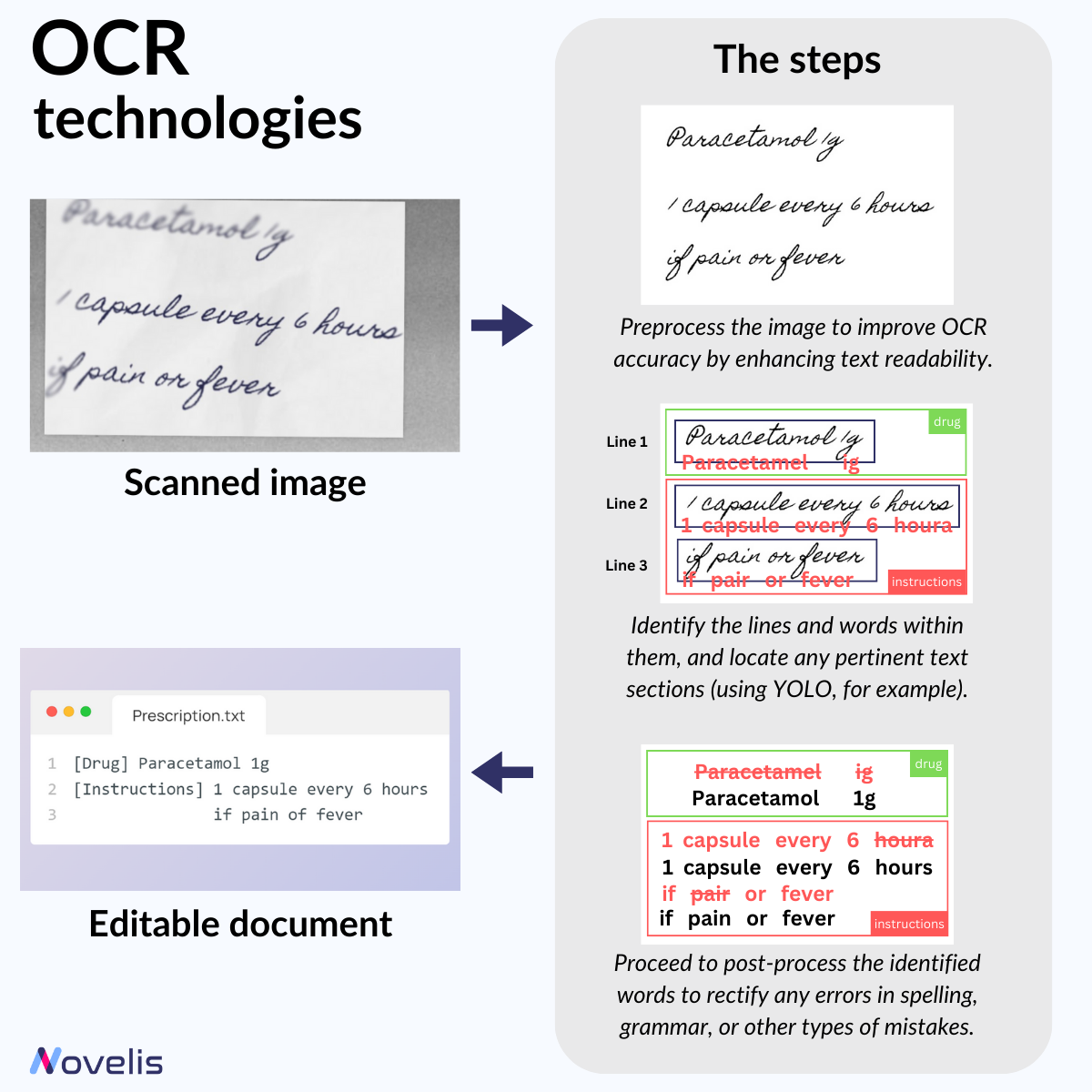
OCR and IDP: A technology that converts printed text into machine-readable text
The Magic of Optical Character Recognition
Have you ever wondered how Intelligent Document Processing (IDP) works? It involves, among other things, converting scanned or handwritten text into editable and searchable text. This process is made possible thanks to Optical Character Recognition (OCR) technologies. In our ongoing series on computer vision tasks (check out our previous post on YOLO), we’ll closely examine OCR and how it works.
When converting an image into text, OCR goes through several steps. First is the pre-processing phase, where the image is cleaned and enhanced to make the text more readable. Next, we move on to the actual character recognition process. Earlier OCR methods identified individual characters or words and compared them to known patterns to extract information. However, most modern OCR methods use neural networks trained to automatically recognize complete lines of text instead of individual characters. The last phase is post-processing, primarily to do error correction. Object Detection methods, like YOLO, can also be used to recognize relevant fields and text regions in documents.
Tesseract is the leading commercial-grade OCR software due to its high customizability and support for numerous languages. Other algorithms, such as the “OCR-free” DONUT, are gaining popularity.
Why is this essential? OCR technologies enable businesses to accelerate their workflows and individuals to access information effortlessly. It drives innovation and revolutionizes healthcare, finance, education, and legal services.
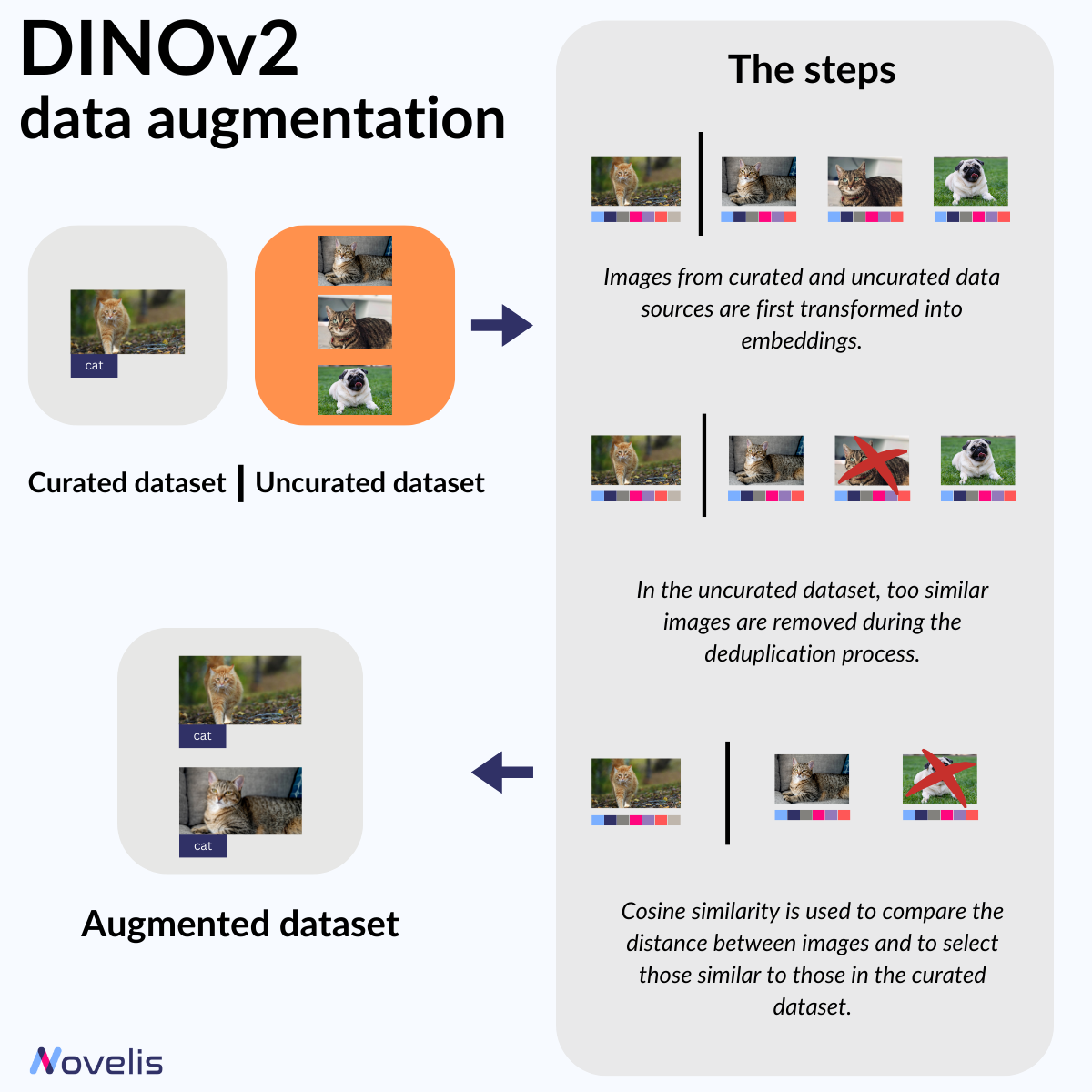
DINOv2: A vision Transformer model that produces universal features suitable for image-level visual tasks
DINOv2: The Next Revolution in Computer Vision?
The field of computer vision is constantly evolving. In our previous posts, we have discussed various methods used in computer vision. However, these approaches often require a large amount of labeled images to achieve good results. Meta Research’s DINOv2 (short for “self-DIstillation with NO labels”) is an innovative computer vision model that utilizes self-supervised learning to remove the need for image labeling.
Simply put, DINOv2 operates without manually labeling each image, a typically time-consuming process. While the model architecture itself is interesting (it follows the masked modeling method that’s very popular in NLP), the data curation process makes DINOv2 such an exciting piece of technology. It first uses embeddings to compare images from a small curated dataset with images from a larger uncurated dataset, then removing similar images from the uncurated dataset to avoid redundancy. Then, it uses cosine similarity to identify and select images similar to those in the curated dataset to label and augment the curated one.
The latest version of DINOv2 was introduced by Meta Research in April 2023. It can be used in various visual applications, both for image and video, including depth estimation, semantic segmentation, and instance retrieval.
Why is this essential? With DINOv2, you can save time by avoiding the tedious and time-consuming task of manually labeling images. This powerful model makes creating precise and adaptable computer vision pipelines easy. It is particularly useful for specialized industries such as medical or industrial, where obtaining labeled data can be costly and challenging.
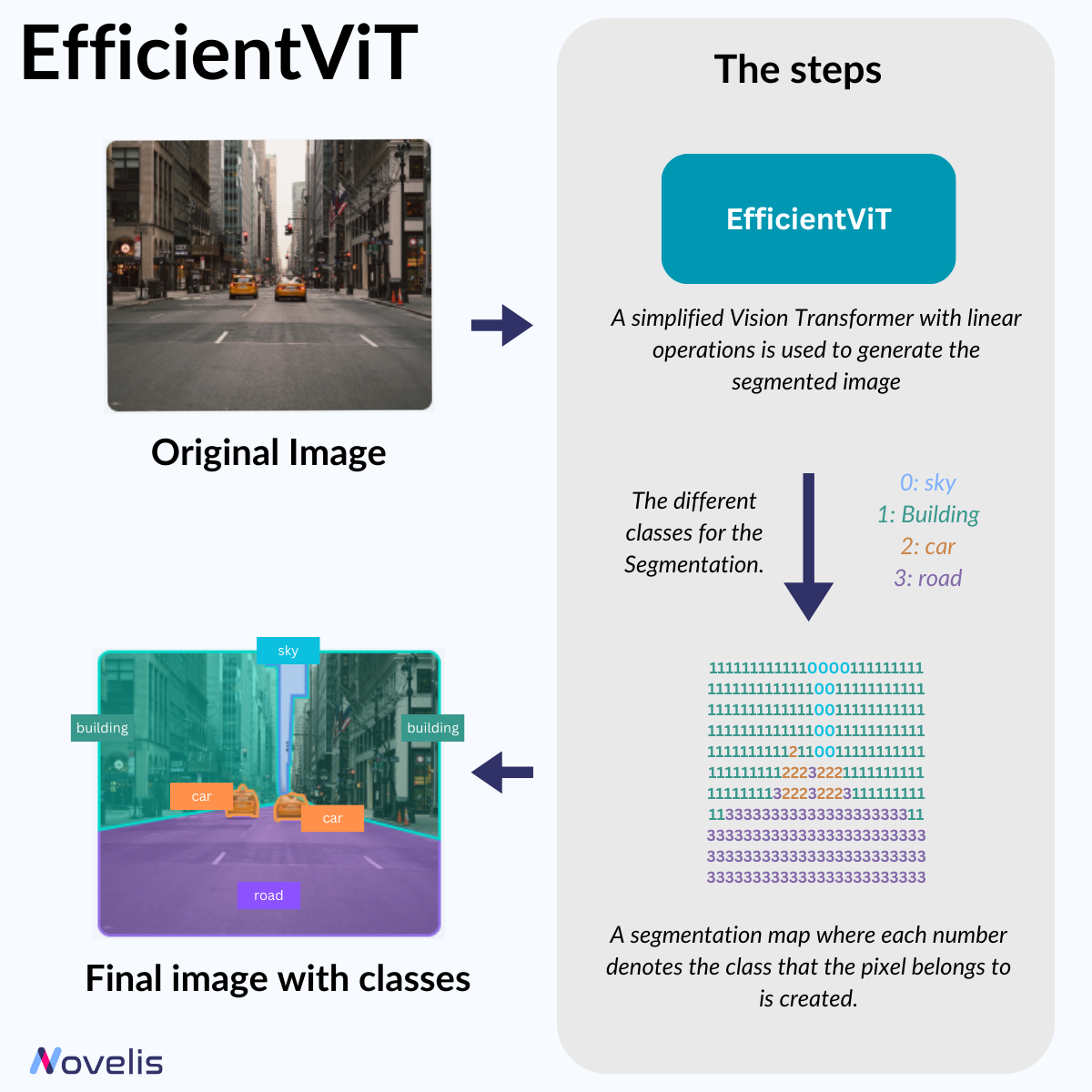
Efficient ViT: A high-speed vision model for efficient high-resolution dense prediction vision tasks
Accelerated Attention for High-Resolution Semantic Segmentation
When it comes to real-time computer vision, like with self-driving cars, recognizing objects quickly and accurately is crucial. This is achieved through semantic segmentation, which analyzes high-resolution images of the surroundings. However, this method requires a lot of processing power. To make it work on devices with limited hardware, a group of scientists from MIT have developed a computer vision model that drastically reduces computational complexity.
EfficientViT is a new vision transformer that simplifies building an attention map. To do this, the researchers made two changes. First, they replaced the nonlinear similarity function with a linear one. Second, they changed the order of operations to reduce the number of calculations needed while maintaining functionality. Two elements accomplish this: the first captures local feature interactions, and the second helps detect small and large objects. The simplified Vision Transformer with linear operations generates the segmented image. The output is a segmentation map where each number denotes the class the pixel belongs to, effectively tagging the input image with the correct labels.
This work is primarily done for academic purposes. However the MIT-IBM Watson AI Lab and other organizations have made their work publicly available in 2022 on their GitHub, and updates are continuously being added.
Why is this important? Reducing computational complexity is necessary for real-time image segmentation on small devices like smartphones or onboard systems with limited computing power.
GPT-4, released by OpenAI in 2023, is the language model that holds one of the largest neural networks ever created, far beyond the language models that came before it. It is also the latest large multimodal model capable of processing images and text as input and producing text as output. Not only does GPT-4 outperform existing models by a considerable margin in English, but it also demonstrates great performance in other languages. GPT-4 is an even more powerful and sophisticated model than GPT-3.5, showing unparalleled performance in many NLP (natural language processing) tasks, including translation and Q&A.
In this article, we present the ten Large Language Models (LLMs) that have had a significant impact on the evolution of NLP in recent years. These models have been specifically designed to tackle various tasks in the Natural Language Processing (NLP), such as question answering, automatic summarization, text-to-code generation, and more. For each model, we have provided an overview of its strengths and weaknesses as compared to other models in its category.
A LLM (Large Language Model) model is trained on a large corpus of text data, designed to generate text like humans. The emergency of LLMs such as GPT-1 (Radford et al., 2018) and BERT (Devlin et al., 2018) was a breakthrough for artificial intelligence.
The first LLM, developed by OpenAI, is GPT-1 (Generative Pretrained Transformer) in 2018 (Radford et al., 2018). It is based on Transformer (Vaswani et al., 2017) neural network, but it has 12 layers and 768 hidden units per layer. The model was trained to predict the next token in a sequence, given the context of the previous tokens. GPT-1 is capable of performing a wide range of language tasks, including answering questions, translating text, and generating creative writing. Since it is the first LLM, GPT-1 has some limitations, for example:
Bias- GPT-1 is trained on a large corpus of text data, which can introduce biases into the model;
Lack of common sense: being trained from texts it has difficulties in linking knowledge to some form of understanding of the world;
Limited interpretability: since it has millions of parameters, it is difficult to interpret how it makes decisions and why it generates certain outputs.
In the same year as GPT-1, Google IA introduced BERT (Bidirectional Encoder Representations from Transformers). Unlike GPT-1, BERT (Devlin et al., 2018) focused on pre-training the model on a masked language modeling task, where the model was trained to predict missing words in a sentence given the context. This approach allowed BERT to learn rich contextual representations of words, which led to improved performance on a range of NLP tasks, such as sentiment analysis and named entity recognition. BERT shares with GPT-1 some limitations, for example, the lack of common sense knowledge about the world, and the limitation in the interpretability to know how it takes decisions and the reason behind to generate some outputs. Moreover, BERT only uses a limited context to make predictions, which can result in unexpected or nonsensical outputs when the model is presented with new or unconventional information.
In the early 2019, surged the third LLM introduced by OpenAI, known as GPT-2 (Generative Pretrained Transformer 2). GPT-2 (Radford et al., 2019) was designed to generate coherent and human-like text by predicting the next word in a sentence based on the preceding words. Its architecture is based on a transformer neural network, similar to its predecessor GPT-1, which uses self-attention to process input sequences. However, GPT-2 is a significantly larger model than GPT-1, with 1.5 billion parameters compared to GPT-1’s 117 million parameters. This increased size enables GPT-2 to generate higher quality text and perform well on a wide range of natural language processing tasks. Additionally, GPT-2 can perform a wider range of tasks, such as summarization, translation, and text completion, compared to GPT-1. However, one limitation of GPT-2 is its computational requirements, which can make it difficult to train and deploy on certain hardware. Additionally, some researchers have raised concerns about the potential misuse of GPT-2 for generating fake news or misleading information, leading OpenAI to initially limit its release.
GPT-2 has been followed by other models such as XLNet and RoBERTa. XLNet (Generalized Autoregressive Pretraining for Language Understanding) was introduced by Google IA. XLNet (Yang et al., 2019) is a variant of the Transformer-based architecture. XLNet is different from traditional
Transformer-based models, such as BERT and RoBERTa, because it uses a permutation-based training method that allows the model to consider all possible word orderings in a sequence, rather than just a fixed left-to-right or right-to-left order. This approach leads to improved performance on NLP tasks such as text classification, question answering, and sentiment analysis. It has state-of-the-art results of NLP benchmark datasets, but like any other model has some limitations. For instance, it has a complex training algorithm (it uses a permutation-based training algorithm), and it needs a large amount of high-quality, diverse training data to perform well.
Simultaneously, RoBERTa (Robustly Optimized BERT Pretraining Approach) was also introduced in 2019, but by Facebook AI. RoBERTa (Liu et al., 2019) improves upon BERT by training on a larger corpus of data, dynamic masking , and training with the whole sentence, rather than just the masked tokens. These modifications lead to improved performance on a wide range of NLP tasks, such as question answering, sentiment analysis, and text classification. RoBERTa is a highly performance LLM, but it has also some limitations. For example, since RoBERTa has a large number of parameters, the inference can be slow; the model is has better proficiency in English, but it does not have the same performance in other languages.
Few months later, Salesforce Research Team released CTRL (Conditional Transformer Language Model). CTRL (Keskar et al., 2019) is designed to generate text conditioned on specific prompts or topics, allowing it to generate coherent and relevant text for specific tasks or domains. CTRL is based on a transformer neural network, similar to other large language models such as GPT-2 and BERT. However, it also includes a novel conditioning mechanism, which allows the model to be fine-tuned for specific tasks or domains. One advantage of CTRL is its ability to generate highly relevant and coherent text for specific tasks or domains, thanks to its conditioning mechanism. However, one limitation of its that it may not perform as well as more general-purpose language models on more diverse or open-ended tasks. Moreover, the conditioning mechanism used by CTRL may require additional preprocessing steps or specialized knowledge to set up effectively.
In the same month as CTRL model, NVIDIA introduced MEGATRON-LM (Shoeybi et al., 2019). MEGATRON-LM is designed to be highly efficient and scalable, enabling researchers and developers to train massive language models with billions of parameters using distributed computing techniques. Its architecture is similar to other large language models such as GPT-2 and BERT. However, Megatron-LM uses a combination of model parallelism and data parallelism to distribute the workload across multiple GPUs, allowing it to train models with up to 8 billion parameters. However, one limitation of Megatron-LM is its complexity and high computational requirements, which can make it challenging to set up and use effectively. Additionally, the distributed computing techniques used by Megatron-LM can introduce additional overhead and communication costs, which can affect training time and efficiency.
Subsequently, a few months later, Hugging Face developed a model called DistilBERT (Aurélien et al., 2019). DistilBERT is a light version of BERT model. It was designed to provide a more efficient and faster alternative to BERT, while still retaining a high level of performance on a variety of NLP tasks. The model is able to achieve up to 40% smaller model sizes and 60% faster inference times compared to BERT, without sacrificing much of its performance accuracy. DistillBERT can perform well in tasks such as sentiment analysis, question answering, and named entity recognition. However, DistillBERT does not perform as well on some NLP tasks as BERT. As well, it has been pre-trained on a smaller dataset compared to BERT, which limits its ability to transfer its knowledge to new tasks and domains.
Simultaneously, Facebook AI released BART (Denoising Autoencoder for Regularizing Translation) in June 2019. BART (Lewis et al., 2019) is a sequence-to-sequence (Seq2Seq) pre-trained model for natural language generation, translation, and comprehension. BART is a denoising autoencoder that uses a combination of denoising objectives in the pre-training. The denoising objectives help the model to learn robust representations. BART has limitations for multi-language translation, its performance can be sensitive to the choice of hyperparameters, and finding the optimal hyperparameters can be a challenge. Additionally, the autoencoder of BART has limitations, such as a lack of ability to model long-range dependencies between input and output variables.
Finally, we highlight the T5 (Transfer Learning with a Unified Text-to-Text Transformer) model, which was introduced by Google AI. T5 (Raffel et al., 2020) is a sequence to-sequence transformer-based. It uses the MSP (Masked Span Prediction) objective in the pre-training, which it consists in randomly masking spans of text with arbitrary lengths. Later, the model predicts the masked spans. Although T5 achieved results in the state of the art, T5 is designed to be a general-purpose text-to-text model, which can sometimes result in predictions that are not directly relevant to a specific task or are not in the desired format. Moreover, T5 is a large model, and it requires a high memory usage, and sometimes takes long time in the inference.
In this article, we have point out the pros and cons of the ten groundbreaking LLMs that have emerged over the last five years. We have also delved into the architectures that these models were built upon, showcasing the significant contributions they have made in advancing the NLP domain.
With the rapid advancement of technology, businesses are constantly striving to streamline their processes and minimize the resources and time required for repetitive tasks. Robotic Process Automation (RPA) has emerged as a popular solution to help achieve these goals, and Novelis, a leading system integrator company, has developed a ChatGPT connector that significantly enhances the capabilities of RPA software, particularly SS&C Blue Prism.
How does the ChatGPT connector enhance SS&C Blue Prism?
The ChatGPT connector, a cutting-edge technology developed by Novelis, offers SS&C Blue Prism the ability to interact with ChatGPT and leverage its advanced natural language processing capabilities. With this integration, SS&C Blue Prism can automate more complex processes that require language-based interactions, such as customer service or data analysis. By harnessing the power of ChatGPT, SS&C Blue Prism can provide faster and more accurate responses to customer inquiries, leading to increased customer satisfaction and improved business outcomes. This innovative solution allows SS&C Blue Prism to stay ahead of the curve in the rapidly evolving landscape of automation technology.
Use Cases and Usages
There are numerous use cases for the ChatGPT connector in SS&C Blue Prism, including:
Customer Service: With the ChatGPT connector, SS&C Blue Prism can automate customer service interactions by understanding natural language and responding appropriately. This can significantly reduce the workload for customer service agents, freeing them up to focus on more complex inquiries.
Data Analysis: ChatGPT can analyze unstructured data such as customer feedback, social media posts, or reviews, and provide insights that can be used to improve business processes. SS&C Blue Prism can use the ChatGPT connector to automate the analysis of this data, providing valuable insights in real-time.
Workflow Automation: Blue Prism can use the ChatGPT connector to automate complex workflows that require language-based interactions, such as document processing or contract management. This can significantly reduce the time and resources required for these processes, improving efficiency and productivity.
The ChatGPT connector developed by Novelis is a valuable tool for businesses that use SS&C Blue Prism to automate their processes. By giving SS&C Blue Prism access to advanced natural language processing capabilities, businesses can streamline their workflows and improve efficiency. Whether it’s automating customer service interactions, analyzing unstructured data, or streamlining complex workflows, the ChatGPT connector is a powerful tool for businesses seeking to increase automation and reduce workload.
About SS&C Blue Prism
SS&C Blue Prism is the global leader in intelligent automation for the enterprise, transforming the way work is done. SS&C Blue Prism have users in over 170 countries in more than 1,800 businesses, including Fortune 500 and public sector organizations, that are creating value with new ways of working, unlocking efficiencies, and returning millions of hours of work back into their businesses. Their intelligent digital workforce is smart, secure, scalable and accessible to all; freeing up humans to re-imagine work.
About ChatGPT
ChatGPT is a language model developed by OpenAI. The goal is to provide quality assistance by answering questions and generating human-like responses to facilitate communication and information exchange. ChatGPT has been trained on a vast corpus of text data and has the ability to understand and respond to a wide range of topics and subjects.
CoEs, often also called “knowledge centers”, have been used in recent years to share accumulated knowledge in different areas such as marketing, pharmaceuticals, automotive, and telecommunications. A CoE can be defined as a group of highly skilled experts who work together to analyze knowledge in a specific area of interest and provide the company with the necessary support to implement technologies in compliance with recommended best practices.
Similarly, an Automation CoE focuses on integrating a strong framework and successful implementation of automation tools within the company.
Benefits of the Automation Center of Excellence
Robotic Process Automation (RPA) has become a must-have for companies looking to increase their operational performance. However, to achieve an even higher level of automation that is adaptable and scalable, intelligent automation is necessary. This is where the crucial role of automation centers of excellence (CoEs) comes in.
CoEs enable rapid digital transformation while controlling associated risks and ensuring that automation investments are managed wisely. By establishing a CoE, companies can effectively manage and monitor their initiatives with total transparency. The automation CoE thus lies at the intersection of control, speed, and agility.
Efficient robot development cycle:
An effective Automation Center of Excellence (CoE) helps companies to centralize knowledge and learning data in the field of automation. It also provides access to best practices shared by other business units, focusing on researching RPA platforms and automation processes. This information sharing enables companies to optimize their time, speed up RPA deployment, and simplify automation-related initiative management.
Integration of IT and RPA:
A well-structured CoE ensures the participation of IT in the project team, where they were previously considered an optional addition. IT teams manage aspects such as infrastructure, security, data confidentiality, and other strategic elements from the start of a project, reducing the risk of automation disruptions. Legacy computer systems are constantly evolving and are regularly updated, which can alter automation at the user interface level. IT teams can help prepare for and anticipate these changes.
Scalability Ease:
Uncoordinated RPA projects can hinder success and prevent companies from achieving desired levels of automation and organizational objectives. A CoE is critical in preventing these types of failures and establishing a comprehensive vision for the company that allows for easy adaptation of RPA. If the goal is to implement automation throughout the organization, a CoE is essential for successful adoption and promotion of RPA or any other automation software.
Improved Return on Investment (ROI):
The absence of a CoE can lead to significant costs for integrating RPA technology, as well as difficult-to-identify inefficiencies that hinder automation, RPA acquisition, and support. A thorough evaluation of potential process automation can help avoid a negative return on investment when investing in a project. Multiple factors must be considered, and in some cases, RPA may not be the best solution for improving processes.
CoE speeds up the deployment of AI.
Deployment of AI
In a recent study by AI experts, “64% reported that it took their organization at least a month to implement a new model, and 20% reported “6 months or more”.”
This is where the automation center of excellence (CoE) can make a significant difference. It achieves three critical outcomes:
It streamlines deployment to accelerate time-to-market.
It sets the standard by determining the elements needed for a profitable business plan.
It optimizes resource utilization to execute projects with increased efficiency and significantly reduced expenses.
How do CoEs achieve these results?
An effective automation CoE uses enterprise platforms and human-automation collaboration to enable rapid integration of models into workflows. This not only allows system robots to access and apply these models in real-time, but also creates conditions for continuous improvement of models using human feedback. Additionally, they drive automated extraction, transformation, quality assurance, and data management with centralized governance and compliance to standards.
The automation CoE goes beyond just “time” considerations to achieve large-scale automation. It seamlessly integrates technology, processes, and people to deliver value-oriented business outcomes while improving operational efficiency and costs. By taking a business-oriented approach rather than simply adopting technology, it links business context to robotic process automation (RPA), AI-based technologies, process mining, and advanced analytics – and thus provides transformative results at all levels of the enterprise. This approach tackles the process fragmentation that poses a challenge to organizations. The CoE therefore shifts from the logic of automating tasks and enterprise processes to that of intelligent automation.
Client testimonials, white papers, articles, webinars… Throughout the year, Novelis teams have created a lot of content to share with you the best practices and feedback on intelligent process automation. In this article, you’ll find our most popular content for 2022 to kick off 2023 and identify the levers that will boost your operational efficiency!
[WHITE PAPER] How automation can help you overcome customer relationship challenges: “Consumer expectations have changed and customer experience has become a major differentiator, especially since its quality is increasingly measurable and comparable. […] Novelis offers you to discover the benefits in its white paper “How automation can help you overcome customer relationship challenges” divided in three parts…”
[USE CASES] RPA: Tasks with high automation potential in finance: “The digital revolution is changing the face of the financial sector, regardless of the business line: treasury, management control, accounting, finance management, etc. Transforming to innovate is becoming an obligation for these players, who must be ever faster, more reliable and more efficient in the execution of processes.”
[USE CASES] RPA: tasks with high automation potential in insurance and for mutual: “Insurance and mutual insurance companies are facing new issues and challenges every day. RPA provides an answer to these challenges, making it a truly essential solution for these insurance and mutual organizations, which have a wide range of processes with high automation potential.”
In this article we will discover the Yolov7 model, an object detection algorithm. We will first study its use and its characteristics through a public dataset. Then we will see how to train this model ourselves from this dataset. Finally, we will train Yolov7 to identify custom objects from our own data.
What is Yolo? Why Yolov7 ?
Yolo is an algorithm for detecting objects in an image. The goal of object detection is to automatically classify, using a neural network, the presence and position of humanly identifiable objects in an image. The interest is therefore based on the capacities and performances in terms of detection, recognition and localization of the algorithms, which have multiple practical applications in the image domain. Yolo’s strength lies in its ability to perform these tasks in real time, which makes it particularly useful with video streams of tens of images per second.
YOLO is actually an acronym for “You Only Look Once”. Indeed, unlike many detection algorithms, Yolo is a neural network that evaluates the position and class of identified objects from a single end-to-end network that detects classes using a fully connected layer. Yolo therefore only needs to “see” an image once to detect the objects present, where some algorithms only detect regions of interest, before re-evaluating these to identify the classes present. Before mentioning the other versions of Yolo, it seems important here to explain the different metrics used to compare the accuracy and efficiency of a model.
Intersection over Union : IoU
Intersection over Union (literally Intersection over Union, or IoU) is a metric for measuring the accuracy of object location. As its name indicates, it is calculated from the ratio between the intersection area of the detected object and the union area of these same objects (see equation 1). By noting Adetected and Aactualthe respective areas of the object detected by YOLO and the object as actually located on the image, we can then write :
Note that an IoU of 0 indicates that the 2 areas are completely distinct and that an IoU of 1 indicates that the 2 objects are perfectly superimposed. In general, an IoU > 0.5 represents a valid localization criterion.
(mean) Average Precision : mAP
Average Precision is a classification accuracy metric. It is based on the average of the correct predictions over the total predictions. So we try to get closer to a 100% mAP score (no error when determining the class of an object).
Coming back to our previous point, Yolo remains an architecture model, and not the property of a particular developer. This explains why the versions of Yolo are from different contributors. Indeed, we increment the version of Yolo (Yolov7 to date: January 2023) each time the previously mentioned metrics (especially the mAP and its associated execution time) clearly exceed the previous model and thus the state of the art. Thus, each new YolovX model is actually an improvement shown by an associated research paper published in parallel.
How does Yolo work?
Yolo works by segmenting the image that it analyzes. It will first grid the space, then perform 2 operations: localization and classification.
Figure 1: Architecture of the Yolo model, operating a grid from successive convolutions
Figure 2: Gridded image
First, Yolo identifies all the objects present with the help of frames by associating them a degree of confidence (here represented by the thickness of the box).
Figure 3: Location of objects
Then, the algorithm assigns a class to each box according to the object that it believes it has detected from the probability map.
Figure 4: Class probability map
Figure 5: Object detection
Finally, Yolo removes all unnecessary boxes using the NMS method.
NMS : Non-Maxima Suppression
The NMS method is based on a path of the high confidence index boxes, then a removal of the boxes superimposed on those by measuring the IoU. For this, we follow 4 steps. Starting from the complete list of detected boxes:
Remove all boxes with a low confidence index.
Identification of the box with the highest confidence index.
Deleting all boxes with too large IoU (i.e. all boxes too similar to our reference box).
Ignoring the reference box thus used, repeat steps 2) and 3) until all boxes in our original list have been eliminated (i.e. taking the 2nd largest confidence index box, then the 3rd, etc.).
We then obtain the following result:
Figure 6: Post-NMS output image showing the objects detected by Yolo
How to use Yolov7 with the COCO dataset ?
Now that we have seen the Yolo model in detail, we will study its use with an image database: the COCO dataset. The MICROSOFT COCO dataset (for Common Objects in COntext), more commonly called MS COCO, is a set of images representing common objects in a common context. However, unlike the usual databases used for object detection and recognition, MS COCO does not present isolated objects or scenes. Indeed, the goal when creating this dataset was to have images close to real life, in order to have a more robust training base for classical image streams, reflecting daily life.
Figure 7: Examples of isolated objects
Figure 8: Examples of isolated scenes
Figure 9: Classical scenes of everyday life.
Thus, by training our Yolov7 model with the MS COCO dataset, it is possible to obtain a recognition algorithm of nearly a hundred classes and categorizing the majority of objects, people and elements of everyday life. Finally, MS COCO is today the main reference for measuring the accuracy and efficiency of a model. To get an idea, below are the results of the different versions of Yolo.
Figure 10: Average Precision (AP) versus analysis time per image
On the x-axis, the times given to the networks to evaluate an image are indicated. The lower the time, the more we can afford to send a large flow of images to our algorithm, at the cost of accuracy. On the ordinate, the average accuracy of the models is indicated as a function of the time allowed, as seen previously.
We then notice 3 important points:
Regardless of the time given to the network, Yolov7 outperforms the other Yolo models in terms of detection accuracy on the MS COCO dataset. This explains its presence as a reference in the current state of the art of real-time image-based object detection.
The increase of the inference time on each image has no/few interest once the 30ms/image is exceeded. This implies that the model is more optimal on a use requiring fast image processing, such as a video stream (> 25 fps).
Regardless of the model concerned, none of them exceeds 57% of detection accuracy. This implies that the model is still far from being able to be used reliably in a public setting.
To obtain the above results yourself, just follow the instructions on the GitHub page of the yolov7 model pre-trained from the MS COCO dataset: https://github.com/WongKinYiu/yolov7.
First, follow the heading :
Installation.
Then the sidebar:
Testing.
How to train Yolov7 ?
Now that we have seen how to test Yolov7 with a dataset on which it is trained, we are going to look at how we can train Yolov7 with our own dataset. We will first start a training with already prepared data, here the MS COCO dataset. Again, the Yolov7 GitHub has a specific insert for this purpose:
Training.
It is broken down into 2 simple steps:
Download the already annotated MS COCO dataset.
Launch the script ” train.py ” intrinsic to the Git directory with the dataset previously downloaded.
This one will then run on 300 steps to conform to the MS COCO dataset. It should be noted that in reality this operation has more of an instructive purpose since Yolov7 is already trained on the MS COCO dataset and thus already has an adequate model.
Prepare your own training data
Now that we have seen what Yolov7 is, how to test it and train it, we just have to provide it with our own image base to train it on our use case. We will therefore follow 4 steps to create our own dataset directly usable to train Yolov7 :
Choice of our image database.
Optional: Labeling of all our images.
Preparation of the launch (use case of Google Collab).
Training (and split operation).
To illustrate the sequence of these operations, we will take a case similar to the Novelis work used on AIDA: the detection of elements drawn on a sheet of paper.
Figure 11: Starting image: a handwritten color drawing on a sheet
To start, we will need to get a sufficient quantity of similar images. Either from our own collection, or by using a pre-existing database (for example by taking the dataset of our choice from this link. On our part, we will use the Quick Draw dataset. Once our database is formed, we will annotate our images. For that, many softwares exist, most of the time allowing to create boxes, or polygons, and to label them as a class. In our case, our database is already labeled, otherwise we would have to create a class for each element to be detected, and then identify by hand on each image the exact areas of presence of these classes. Once our dataset is labelled, we can launch a session on Google Colab and start a new Python Notebook. We will call it “MyYolov7Project.ipynb” for example.
First step: copy your dataset in your drive. In our case, we have already added to our drive a folder “Yolov7_Dataset”. Here is the tree structure of the folder:
Figure 12: Tree structure of the “Yolov7_Dataset” folder
For each folder, there is an images folder, containing the images, and a labels folder containing the associated labels generated previously. In our case, we use 20 000 images in total, including 15 000 for training, 4 000 for validation and 1 000 for testing.
The data.yaml file contains all the paths to the :
Then the characteristics of the classes:
We will not show the 345 classes in detail but they should be present in your file. We can now start our script “MyYolov7Project.ipynb” on Colab. First step, link our Drive to Colab in order to save our results (Be careful : the data of the trained network are voluminous).
Once our Drive is linked, we can now clone Yolov7 from the official Git:
By placing us in the installed folder, we check the prerequisites:
We will also need the sys and torch libraries.
We can then run the training script for our network:
Note that the batch size can be modified according to the capacities of your GPU (with the free version of Collab, 16 is the maximum possible). Don’t forget to modify your path to the “data.yaml” file according to the tree structure of your Drive. At the end of the training, we get a file with the training metrics and a trained model on our database. By launching the detection script (detect.py), we can obtain the detection result on our starting image:
Figure 13: Starting image annotated by Yolov7
As we can see, some elements were not detected (the river, the grass in the foreground) and some were mislabeled (the two mountains perceived as volcanoes, probably due to the sunlight passing by). Our model can therefore be further improved, either by refining our database or by modifying the training parameters.
Optional: Split network training (when using the free version of Google Colab)
Although our use case remains simplistic, when using the free version of Google Colab, the training of our network can take several days before being completed. However, the restrictions of Google Colab (free version) prevent a program to run more than 12 hours. To keep the training, you just have to restart it after stopping a session with our last recorded weight as a parameter (weights):
Here is an example launched with the 8th run (replace the folder “yolov78” by the last training done). You can find all your trainings in the associated folder in the Yolov7 tree.
Figure 14: Training tree. Here we are at the 12th launch
The training then resumes from the last epoch used, and allows you to progress without losing the time previously spent on your network.
References:
Work, experiments and feedback from the R&D Lab.
Contribution de WANG, Chien-Yao, BOCHKOVSKIY, Alexey, et LIAO, Hong-Yuan Mark. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv preprint arXiv:2207.02696, 2022. : https://arxiv.org/abs/2207.02696
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.