Tag : IA

Automatisation des Commandes Client : Un Projet Réussi pour Transformer les Processus

Novelis participe au Salon de l’Intelligence Artificielle du Ministère de l’Intérieur

Le 8 octobre 2024, Novelis participera au Salon de l’Intelligence Artificielle de la Direction de la Transformation Numérique du Ministère de l’Intérieur.
Cet événement, situé au Bâtiment Bercy Lumière à Paris, vous plongera dans le monde de l’IA à travers des démonstrations, des stands interactifs et des ateliers immersifs. C’est l’occasion idéale de découvrir les dernières avancées technologiques qui transforment nos organisations !
Retrouvez Novelis : Faire de l’IA Générative un atout pour le partage d’informations
Nous vous invitons à venir découvrir comment Novelis révolutionne la manière dont les entreprises capitalisent sur leur savoir-faire et partagent leurs connaissances grâce à l’IA Générative. Sur notre stand, nous mettrons en lumière les enjeux et solutions autour de la transmission fiable et efficace des informations au sein des organisations.
Nos experts El Hassane Ettifouri – Directeur Innovation, Sanoussi Alassan – Docteur en IA et expert en GenAI et Laura Minkova – Data Scientist, seront présents et partageront leurs expertises sur comment l’IA peut transformer votre organisation.
Ne ratez pas l’occasion et venez échanger avec nous pour améliorer l’efficacité de votre entreprise !
[Webinar] Éliminez les approximations de vos initiatives d’automatisation intelligente avec l’intelligence des processus
![[Webinar] Éliminez les approximations de vos initiatives d’automatisation intelligente avec l’intelligence des processus](https://staging.novelis.io/wp-content/uploads/2024/09/FR-1.png)
Avez-vous du mal à savoir comment lancer ou optimiser vos efforts d’automatisation intelligente ? Vous n’êtes pas seul. De nombreuses organisations rencontrent des difficultés à déployer efficacement les technologies d’automatisation et d’IA, gaspillant souvent du temps et des ressources. La bonne nouvelle est qu’il existe un moyen d’éliminer les approximations du processus : Process Intelligence
Rejoignez-nous le 26 septembre pour un webinaire exclusif avec notre partenaire ABBYY, intitulé « Éliminez les approximations de vos initiatives d’automatisation intelligente grâce à l’intelligence des processus ». Au cours de cette session, Catherine Stewart, Présidente des Amériques chez Novelis, partagera son expertise sur la manière dont les entreprises peuvent utiliser le « process mining » et le « task mining » pour optimiser les flux de travail et obtenir un impact réel et mesurable.
Pourquoi assister
L’automatisation a le potentiel de transformer vos opérations commerciales, mais sans la bonne approche, les efforts peuvent facilement échouer. Catherine Stewart s’appuiera sur sa vaste expérience dans la gestion des initiatives d’automatisation pour révéler comment l’intelligence des processus peut aider les entreprises à améliorer leur efficacité, réduire les goulets d’étranglement et garantir un succès à long terme.
Points clés :
- Comment l’intelligence des processus peut fournir des informations critiques sur la performance de vos processus et identifier les inefficacités.
- Le rôle du « task mining » dans la capture des données au niveau des tâches pour compléter le « process mining », offrant ainsi une vue complète de vos opérations.
- Des exemples concrets de la manière dont Novelis a aidé ses clients à optimiser leurs efforts d’automatisation grâce à l’intelligence des processus, entraînant une amélioration de l’efficacité, de la précision et de la satisfaction client.
- L’importance des jumeaux numériques pour simuler les processus métier, permettant des améliorations continues sans affecter les systèmes de production.
Optimisation des agents d’interface utilisateur graphique pour l’ancrage des instructions visuelles utilisant des systèmes d’Intelligence Artificielle multimodale.

Découvrez la première version de notre publication scientifique « Optimisation des agents d’interface utilisateur graphique pour l’ancrage des instructions visuelles utilisant des systèmes d’Intelligence Artificielle multimodale » publiée dans arxiv et soumise à la revue Engineering Applications of Artificial Intelligence. Cet article, rédigé en anglais, est déjà disponible au public.
Merci à l’équipe de recherche de Novelis pour leur savoir-faire et leur expertise.
A propos
Most instance perception and image understanding solutions focus mainly on natural images. However, applications for synthetic images, and more specifically, images of Graphical User Interfaces (GUI) remain limited. This hinders the development of autonomous computer-vision-powered Artificial Intelligence (AI) agents. In this work, we present Search Instruction Coordinates or SIC, a multi-modal solution for object identification in a GUI. More precisely, given a natural language instruction and a screenshot of a GUI, SIC locates the coordinates of the component on the screen where the instruction would be executed. To this end, we develop two methods. The first method is a three-part architecture that relies on a combination of a Large Language Model (LLM) and an object detection model. The second approach uses a multi-modal foundation model.
arXiv est une archive ouverte de prépublications électroniques d’articles scientifiques dans différents domaines techniques, tels que la physique, les mathématiques, l’informatique et bien plus encore, gratuitement accessible par Internet.
Novelis est sponsor du Chief AI Officer USA Exchange en Floride

L’événement Chief AI Officer USA Exchange, prévu pour les 1er et 2 mai 2024, est un rassemblement exclusif, sur invitation uniquement, qui se tiendra à l’hôtel Le Méridien Dania Beach à Fort Lauderdale, en Floride. Conçu pour les cadres dirigeants, il vise à simplifier les complexités de l’Intelligence Artificielle.
Le monde de l’IA évolue à un rythme sans précédent, offrant des opportunités précieuses tout en présentant des défis significatifs. Dans ce paysage complexe, le rôle de cet événement devient crucial pour guider les entreprises à travers les subtilités de l’IA, en maximisant ses bénéfices, le tout en naviguant prudemment pour éviter les pièges éthiques et les préoccupations liées à la vie privée.
- Quel est le rôle du directeur de l’IA ?
- La relation entre l’IA, la confidentialité et la gouvernance des données
- Application concrète de l’IA Générative
- Communication gouvernementale et réglementation
- Création de solutions IA / Machine Learning internes et externes
- Mise en œuvre stratégique et transformation d’entreprise
- Cybersécurité dans l’IA
- Durabilité dans l’IA
Un événement unique auquel Novelis participe
- Réseau exclusif : Rassemblement sélectif de cadres dirigeants dans l’IA et les technologies émergentes. Sur invitation uniquement, pour des discussions diversifiées et pertinentes pour l’industrie.
- Contenu personnalisé : Exploitation de plus de 5 ans de données pour du contenu sur mesure par un panel varié d’experts.
- Fournisseurs sélectionnés : Sponsors choisis pour aborder les défis contemporains, améliorant l’expérience des participants.
Novelis se distingue en tant qu’expert en Automatisation et IA Générative, possédant une expertise dans l’intégration synergique de ces deux domaines. En fusionnant notre connaissance approfondie de l’automatisation avec les dernières avancées en IA Générative, nous offrons à nos partenaires et clients une expertise inégalée, leur permettant de naviguer avec confiance à travers l’écosystème complexe de l’IA.
Novelis sera représentée par Catherine Stewart, Présidente et Directrice Générale pour les Amériques, ainsi que par Paul Branson, Directeur des Solutions Techniques.
Cet événement offre l’occasion de découvrir les rôles émergents dans l’IA, discuter d’études de cas pertinentes et de stratégies éprouvées pour une intégration réussie de l’IA en entreprise.
Retrouvons-nous pour discuter de vos projets d’IA et d’Automatisation.
Découvrez les différentes technologies existantes dans le domaine de la modélisation linguistique, en particulier avec les grands modèles de langage (LLM).

StreamingLLM : Permettre aux LLM de répondre en temps réel
StreamingLLM : briser la limitation de contexte court

Avez-vous déjà eu une conversation prolongée avec un chatbot (comme ChatGPT), pour vous rendre compte qu’il a perdu le fil ou n’est plus aussi cohérent ? Ou vous êtes-vous retrouvé face à une limite de longueur d’entrée épuisée avec les API de certains fournisseurs de modèles de langage ? La principale contrainte des LLM est la longueur de contexte limitée, ce qui empêche des interactions prolongées et de tirer pleinement parti de leurs capacités.
Des chercheurs du MIT, de Meta AI et de l’université Carnegie Mellon ont publié un article intitulé « Efficient Streaming Language Models With Attention Sinks ». Cet article présente une nouvelle technique permettant d’augmenter la longueur d’entrée des LLM sans perte d’efficacité ni dégradation des performances, et ce, sans avoir à réentraîner les modèles.
Le cadre StreamingLLM stocke les quatre premiers jetons (appelés « sinks ») dans un cache KV en tant que « Attention Sink » sur des modèles pré-entraînés comme LLaMA, Mistral, Falcon, etc. Ces jetons essentiels résolvent les défis de performance liés à l’attention classique, permettant d’étendre les capacités des LLM au-delà des limites de taille de contexte et de cache. L’utilisation de StreamingLLM aide à réduire la perplexité (indicateur de la capacité d’un modèle à prédire le prochain mot dans un contexte) ainsi que la complexité de calcul du modèle.
Pourquoi est-ce important ? Cette technique permet aux LLM de gérer des séquences de plus de 4 millions de jetons sans réentraînement, tout en minimisant la latence et l’empreinte mémoire par rapport aux méthodes précédentes.
RLHF : Adapter les modèles d’IA grâce à l’intervention humaine
Renforcer l’IA avec l’apprentissage par renforcement à partir du feedback humain
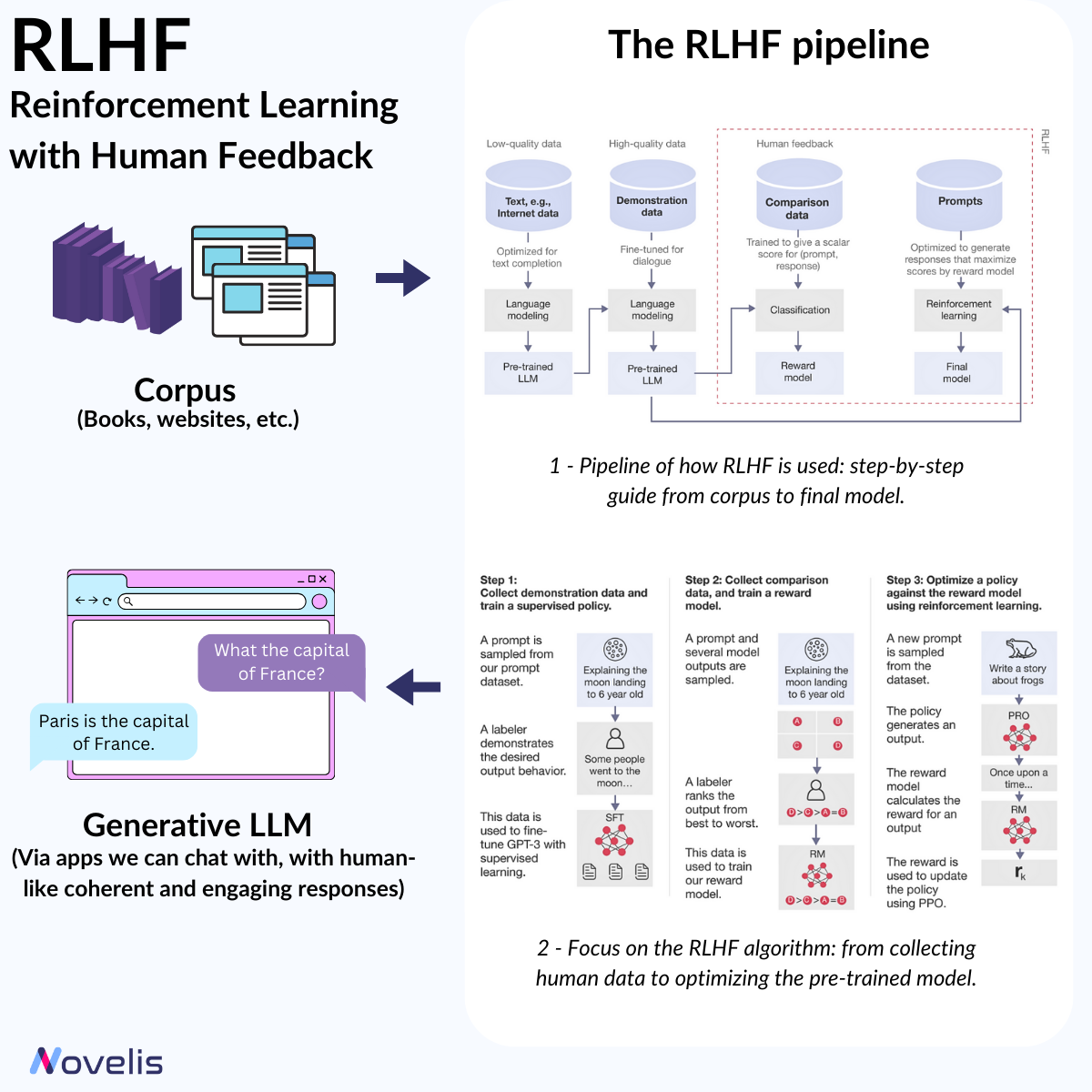
Le Renforcement par l’Apprentissage de Retours Humains (RLHF) est une avancée importante dans le traitement du langage naturel (NLP). Il permet d’ajuster les modèles de machine learning en utilisant l’intuition humaine, rendant les systèmes d’IA plus contextuels. Le RLHF est une méthode d’apprentissage où les modèles d’IA (ici, les LLM) sont affinés via des feedbacks humains. Cela implique de créer un « modèle de récompense » basé sur des retours, qui sert ensuite à optimiser le comportement de l’agent IA par le biais d’algorithmes de renforcement. En pratique, le RLHF permet aux machines d’apprendre et de s’améliorer grâce aux jugements des évaluateurs humains. Par exemple, un modèle d’IA peut être formé pour générer des résumés convaincants ou engager des conversations plus pertinentes en utilisant le RLHF.
Pourquoi est-ce essentiel ? Comprendre le RLHF est crucial pour saisir l’évolution du NLP et des LLM, et comment ils offrent des réponses claires et engageantes. RLHF permet d’aligner les modèles d’IA sur les valeurs humaines en fournissant des réponses plus proches de nos préférences.
RAG : Combiner les LLM avec des bases de données externes
L’efficacité simple du Retrieval Augmented Generation (RAG)
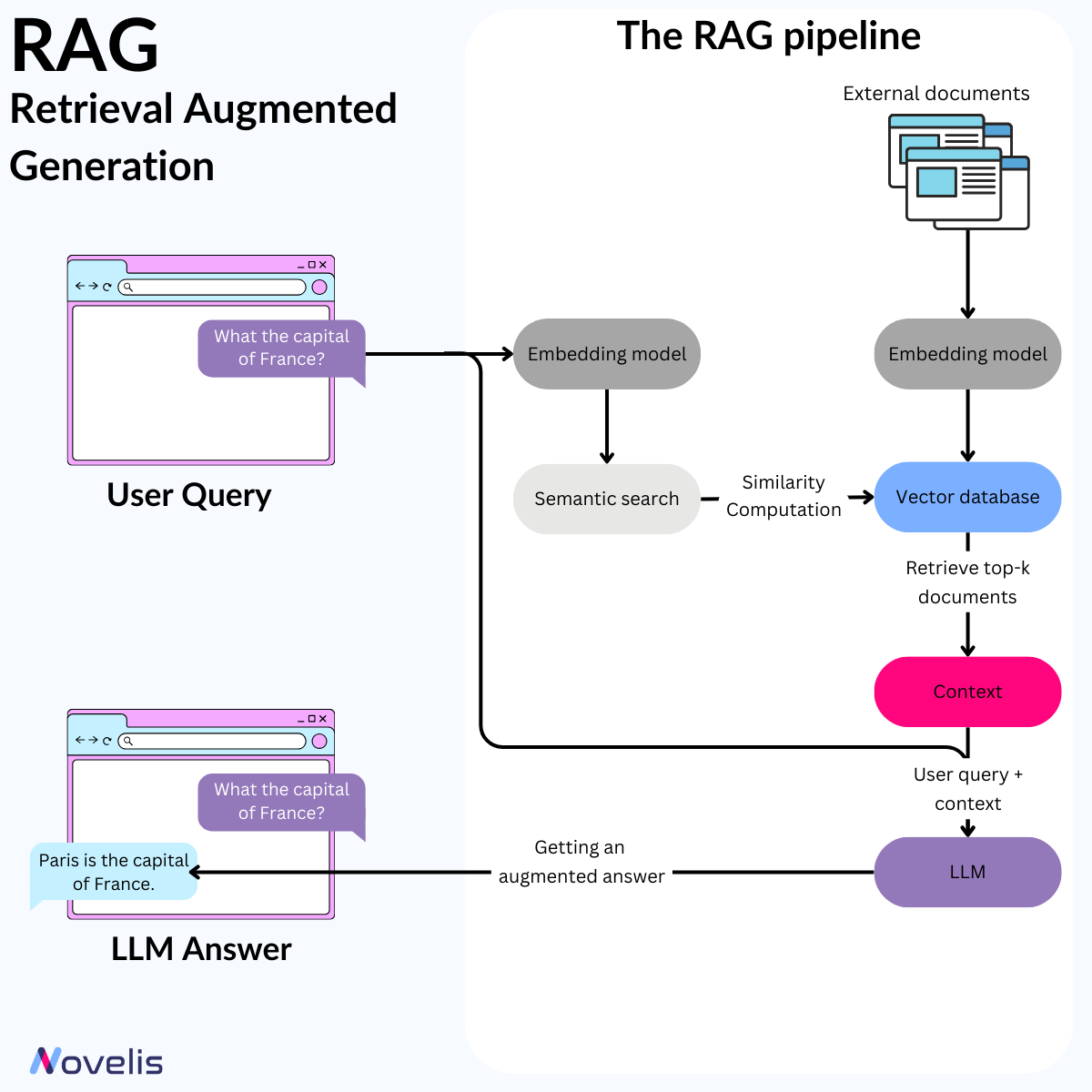
L’intelligence artificielle progresse rapidement avec des modèles comme GPT-4, Mistral, et Llama qui fixent de nouveaux standards. Cependant, ces modèles restent limités par leurs connaissances internes. En septembre 2020, Meta AI a introduit le cadre RAG (Retrieval Augmented Generation), conçu pour améliorer les réponses des LLM en intégrant des sources de connaissance externes et en enrichissant leurs bases de données internes. RAG est un système d’IA qui combine les LLM avec des bases de données externes pour fournir des réponses précises et actualisées.
Pourquoi est-ce essentiel ? Les LLM sont souvent limités par des données obsolètes et peuvent générer des informations erronées. Le RAG résout ces problèmes en assurant une précision factuelle et une cohérence, réduisant la nécessité de réentraîner fréquemment les modèles. Cela permet de diminuer les ressources computationnelles et financières nécessaires au maintien des LLM.
CoT : Concevoir les meilleurs prompts pour obtenir les meilleurs résultats
Chain-of-Thought : les LLM peuvent-ils raisonner ?
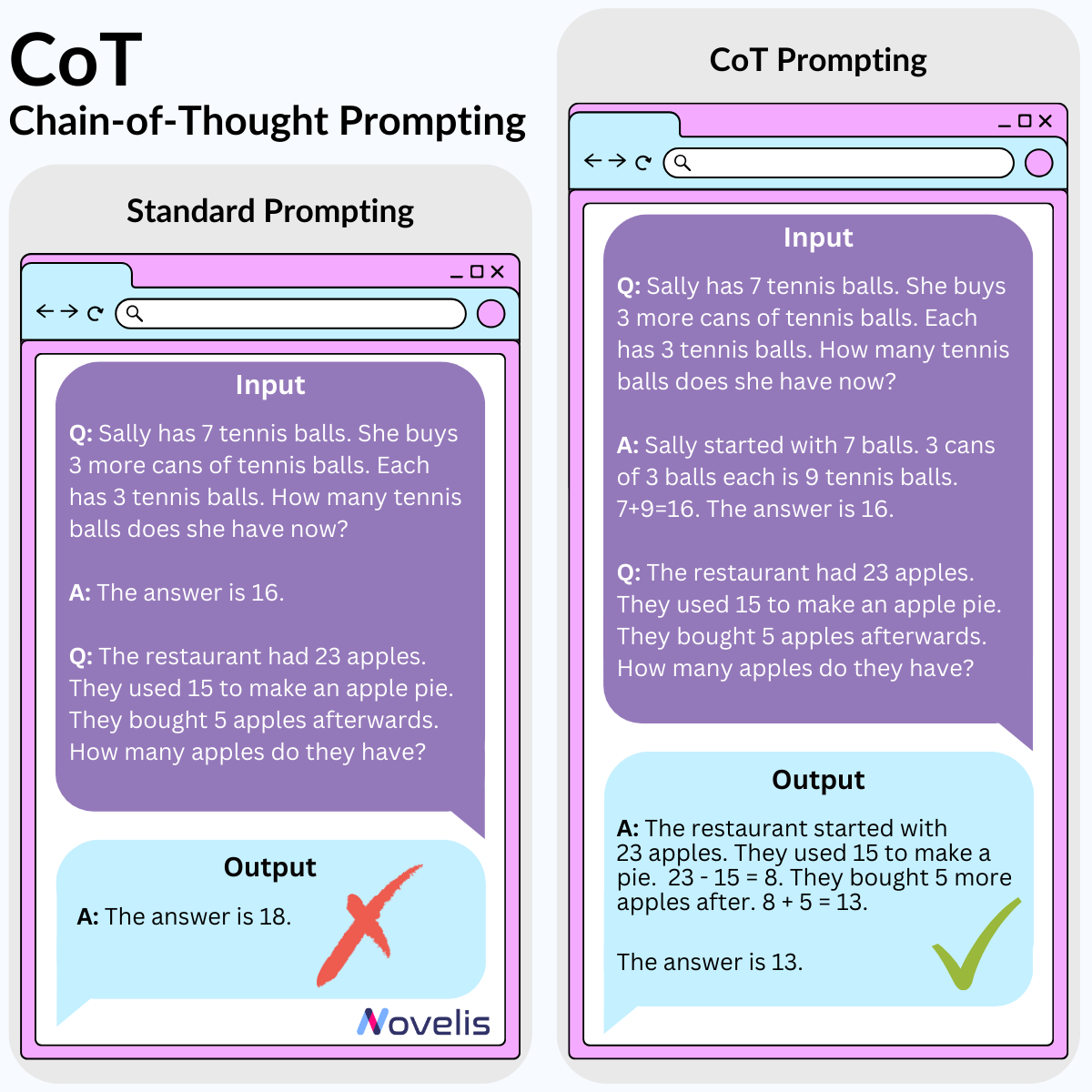
Nous avons exploré comment mieux utiliser les LLM grâce au Chain-of-Thought (CoT), une technique de prompt engineering. Cette méthode consiste à structurer les prompts de manière à décomposer un problème complexe en sous-problèmes plus simples, simulant la façon dont les humains résolvent les problèmes. Cela fonctionne bien pour des tâches de raisonnement arithmétique, de bon sens, et de logique symbolique.
Pourquoi est-ce essentiel ? Appliquer la technique CoT peut améliorer les résultats lorsqu’il s’agit de résoudre des problèmes arithmétiques, de bon sens ou de logique dans les LLM. Cela aide également à comprendre où le modèle pourrait se tromper
Interview d’Olivier Chosson, Directeur des Opérations de Novelis, lors de l’AM Tech Day

Le 3 octobre, Novelis était présent à l’AM Tech Day, l’événement incontournable pour les gestionnaires de portefeuille et les gestionnaires d’actifs organisé par L’AGEFI.
Au cours de cet événement, Olivier Chosson, Directeur des Opérations, a discuté lors d’une interview de la proposition de valeur de Novelis pour accompagner les assets managers dans l’optimisation de la gestion d’actifs grâce à l’IA générative, à l’automatisation et à la cybersécurité.
Retrouvez ci-dessous l’interview :
Adrien : J’ai le plaisir d’accueillir sur le studio de l’AGEFI AM Tech Day, aujourd’hui au Palais Brongniart. Olivier Chosson, Bonjour !
Olivier : Bonjour Adrien.
Adrien : Vous êtes associé et directeur des opérations de Novelis et j’ai naturellement envie de poser la question, Novelis, what is it ?
Olivier : Novelis, c’est un spécialiste de l’efficacité opérationnelle et qui va accompagner ses clients sur l’ensemble de l’étude de leurs processus au travers d’outils tels que le Process Intelligence, l’Automatisation Intelligente. Et puis tous les outils que l’Intelligence Artificielle, notamment l’Intelligence Artificielle Générative, va nous permettre de mettre à disposition. Aussi de travailler sur des architectures innovantes telles que des architectures modulaires et/ou de la cybersécurité, bien évidemment, pour sécuriser l’ensemble des données sur lesquelles on va travailler.
Le cabinet est structuré autour d’un laboratoire de R&D spécialisé dans l’intelligence artificielle. Il emploie exclusivement des chercheurs en intelligence artificielle qui se consacrent à la recherche fondamentale dans ce domaine, contribuant ainsi à faire progresser les modèles. Pourquoi avons-nous pris cette initiative ? Dans le but d’anticiper les évolutions du marché et de proposer à nos clients et partenaires les produits dès qu’ils sont prêts et matures, afin de les rendre opérationnels et de les mettre sur le marché.
Adrien : Alors là vous avez vraiment foncé sur la problématique IA, complètement pour l’embrasser.
Olivier : C’est effectivement notre job et c’est là-dessus qu’on a construit le cabinet maintenant depuis sa naissance il y a un peu plus de 6 ans.
Adrien : Alors, j’aurais demandé à de nombreuses personnes ce qu’elles pensent de l’IA en tant que sujet de demain. Certains abordent ce sujet aujourd’hui, mais pour d’autres, il représente le sujet de demain. Pour vous, c’est déjà un enjeu d’actualité, peut-être même depuis hier et aujourd’hui. Alors, quel est, selon vous, le sujet de demain ?
Olivier : Pour Novelis, l’IA générative deviendra un incontournable dans le monde des entreprises, dès demain. Lorsque nous évoquons l’IA générative, beaucoup de gens pensent à ChatGPT. Cependant, dès aujourd’hui, les entreprises ont la possibilité d’avoir leur propre modèle de ChatGPT, travaillant spécifiquement sur leurs données et leurs processus.
Quel est l’objectif ? Il s’agit d’apporter une valeur considérable, mais pour qui ? Tout d’abord, pour leurs clients. Les entreprises auront la possibilité de proposer des services plus personnalisés, plus rapides, et avec une plus grande valeur ajoutée. Cela apportera également de la valeur à leurs employés. Ces derniers pourront se concentrer sur leurs compétences, développer leur expertise, et ainsi fournir encore plus de valeur à leurs clients. En fin de compte, c’est toute l’entreprise qui pourra ainsi accroître sa valeur.
Adrien : Et c’est ce que vous faites, c’est accompagner ces entreprises dans cette démarche-là.
Olivier : Exactement. Et c’est notre boulot, c’est notre job.
Adrien : Voilà. Et pour celles et ceux qui souhaitent en apprendre davantage, vous pouvez bien sûr vous rendre sur le stand Novelis ici lors de l’AM Tech Day.
Olivier : Exactement.
Adrien : Olivier Chosson, associé et directeur des opérations de Novelis, merci beaucoup.
Olivier : Merci Adrien.
10 premiers grands modèles de langage qui ont transformé le NLP au cours des 5 dernières années

GPT-4, publié par OpenAI en 2023, est le modèle de langage qui détient l’un des plus grands réseaux neuronal jamais créé, bien au-delà des modèles de langage qui l’ont précédé. Il est également le plus récent des grands modèles multimodaux capables de traiter des images et des textes en entrée et de produire des textes en sortie. Non seulement GPT-4 surpasse les modèles existants par une marge considérable en anglais, mais il fait également preuve d’une grande performance dans d’autres langues. GPT-4 est un modèle encore plus puissant et sophistiqué que GPT-3.5, montrant des performances inégalées dans de nombreuses tâches de NLP (traitement du langage naturel), y compris la traduction et les questions-réponses.
Dans cet article, nous présentons dix grands modèles de langage (LLM) ayant eu un impact significatif sur l’évolution du NLP ces dernières années. Ces modèles ont été spécialement conçus pour s’attaquer à diverses tâches dans le domaine du traitement du langage naturel (NLP), telles que la réponse aux questions, le résumé automatique, la génération de texte à partir de code, etc. Pour chaque modèle, vous trouverez un aperçu de ses forces et faiblesses par rapport aux autres modèles de sa catégorie.
Un modèle LLM (Large Language Model) est entraîné sur un grand corpus de données textuelles et est conçu pour générer du texte comme le ferait un humain. L’émergence des LLM tels que GPT-1 (Radford et al., 2018) et BERT (Devlin et al., 2018) a représenté une percée dans le domaine de l’intelligence artificielle.
Le premier LLM, développé par OpenAI, est le GPT-1 (Generative Pretrained Transformer) en 2018 (Radford et al., 2018). Il est basé sur le réseau neuronal Transformer (Vaswani et al., 2017) et comporte 12 couches et 768 unités cachées par couche. Le modèle a été entraîné à prédire le l’élément suivant d’une séquence, compte tenu du contexte des éléments précédents. Le GPT-1 est capable d’effectuer un large éventail de tâches linguistiques, notamment de répondre à des questions, de traduire des textes et de produire des écrits créatifs. Étant donné qu’il s’agit du premier LLM, le GPT-1 présente certaines limites, par exemple :
- Risque de biais : le GPT-1 est entraîné sur un vaste corpus de données textuelles, ce qui peut introduire des biais dans le modèle ;
- Manque de « bon sens » : en étant formé à partir de textes il a des difficultés à lier les connaissances à une forme de compréhension ;
- Interprétabilité limitée : étant donné qu’il a des millions de paramètres, il est difficile d’interpréter la façon dont il prend des décisions et pourquoi il génère certains résultats.
La même année que GPT-1, Google IA a introduit BERT (Bidirectional Encoder Representations from Transformers). Contrairement à GPT-1, BERT (Devlin et al., 2018) s’est concentré sur le pré-entraînement du modèle à partir d’une une tâche de modélisation du langage masqué, où le modèle a été entraîné à prédire les mots manquants dans une phrase compte tenu du contexte. Cette approche a permis à BERT d’apprendre des représentations contextuelles riches des mots, ce qui a conduit à une amélioration des performances sur une gamme de tâches NLP, telles que l’analyse des sentiments et la reconnaissance des entités nommées. BERT partage avec GPT-1 certaines limitations, par exemple, l’absence de connaissances de sens commun sur le monde, et la limitation de l’interprétabilité pour savoir comment il prend des décisions et la raison le poussant à générer certains résultats. En outre, BERT n’utilise qu’un contexte limité pour faire des prédictions, ce qui peut donner lieu à des résultats inattendus ou absurdes lorsque le modèle est confronté à des informations nouvelles ou non conventionnelles.
Au début de l’année 2019, le troisième LLM introduit par OpenAI, connu sous le nom de GPT-2 (Generative Pretrained Transformer 2) est apparu. GPT-2 (Radford et al., 2019) a été conçu pour générer des textes cohérents et de type humain en prédisant le mot suivant dans une phrase en fonction des mots précédents. Son architecture est basée sur un réseau neuronal transformateur, similaire à son prédécesseur GPT-1, qui utilise l’auto-attention pour traiter les séquences d’entrée. Cependant, GPT-2 est un modèle beaucoup plus large que GPT-1, avec 1,5 milliard de paramètres par rapport aux 117 millions de paramètres de GPT-1. Cette taille accrue permet à GPT-2 de générer des textes de meilleure qualité et d’obtenir des résultats améliorés dans un large éventail de tâches de traitement du langage naturel. En outre, le GPT-2 peut effectuer un plus grand nombre de tâches, telles que le résumé, la traduction et la complétion de texte, par rapport à GPT-1. Cependant, l’une des limites de GPT-2 réside dans ses exigences en matière de ressources pour le calcul, ce qui peut rendre difficile sa formation et son déploiement sur certains matériels. En outre, certains chercheurs se sont inquiétés de l’utilisation potentiellement abusive du GPT-2 pour générer des fausses nouvelles ou des informations trompeuses, ce qui a conduit l’OpenAI à limiter sa diffusion dans un premier temps.
GPT-2 a été suivi par d’autres modèles tels que XLNet et RoBERTa. XLNet (Generalized Autoregressive Pretraining for Language Understanding) a été introduit par Google IA. XLNet (Yang et al., 2019) est une variante de l’architecture basée sur Transformer. XLNet est différent des modèles traditionnels.
Transformer, tels que BERT et RoBERTa, utilise une méthode d’apprentissage basée sur la permutation qui permet au modèle de prendre en compte tous les ordres de mots possibles dans une séquence, plutôt qu’un ordre fixe de gauche à droite ou de droite à gauche. Cette approche permet d’améliorer les performances dans les tâches de NLP telles que la classification des textes, la réponse aux questions et l’analyse des sentiments. Ce modèle a obtenu des résultats de pointe sur des ensembles de données de référence en matière de NLP, mais, comme tout autre modèle, il présente certaines limites. Par exemple, son algorithme d’apprentissage est complexe (il utilise un algorithme d’apprentissage basé sur la permutation) et il a besoin d’une grande quantité de données d’apprentissage diversifiées et de haute qualité pour obtenir de bons résultats.
Simultanément, RoBERTa (Robustly Optimized BERT Pretraining Approach) a également été introduit en 2019, mais par Facebook AI. RoBERTa (Liu et al., 2019) améliore BERT en s’entraînant sur un plus grand corpus de données, un masquage dynamique, et en s’entraînant avec la phrase entière, plutôt qu’avec les seuls tokens masqués. Ces modifications conduisent à une amélioration des performances sur un large éventail de tâches NLP, telles que la réponse aux questions, l’analyse des sentiments et la classification des textes. RoBERTa est un LLM très performant, mais il présente également certaines limites. Par exemple, comme RoBERTa a un grand nombre de paramètres, l’inférence peut être lente ; le modèle est plus performant en anglais, mais il n’a pas les mêmes performances dans d’autres langues.
Quelques mois plus tard, l’équipe de recherche de Salesforce a publié CTRL (Conditional Transformer Language Model). CTRL (Keskar et al., 2019) est conçu pour générer du texte conditionné par des sujets spécifiques, ce qui lui permet de générer un texte cohérent et pertinent pour des tâches ou des domaines spécifiques. CTRL est basé sur un réseau neuronal transformateur, similaire à d’autres grands modèles de langage tels que GPT-2 et BERT. Cependant, il comprend également un nouveau mécanisme de conditionnement, qui permet au modèle d’être finement ajusté pour des tâches ou des domaines spécifiques. L’un des avantages de CTRL est sa capacité à générer des textes hautement pertinents et cohérents pour des tâches ou des domaines spécifiques, grâce à son mécanisme de conditionnement. Cependant, l’une de ses limites est qu’il peut ne pas être aussi performant que des modèles linguistiques plus généraux pour des tâches plus diverses ou plus ouvertes. En outre, le mécanisme de conditionnement utilisé par CTRL peut nécessiter des étapes de prétraitement supplémentaires ou des connaissances spécialisées pour être mis en place efficacement.
Le même mois que le modèle CTRL, NVIDIA a présenté MEGATRON-LM (Shoeybi et al., 2019). MEGATRON-LM est conçu pour être très efficace et évolutif, permettant aux chercheurs et aux développeurs de former des modèles de langage massifs avec des milliards de paramètres en utilisant des techniques de calcul distribué. Son architecture est similaire à celle d’autres grands modèles de langage tels que GPT-2 et BERT. Cependant, Megatron-LM utilise une combinaison de parallélisme de modèles et de parallélisme de données pour distribuer la charge de travail sur plusieurs GPU, ce qui lui permet d’entraîner des modèles comportant jusqu’à 8 milliards de paramètres. Néanmoins, l’une des limites de Megatron-LM est sa complexité et ses exigences élevées en matière de calcul, qui peuvent compliquer sa mise en place et son utilisation efficace. En outre, les techniques de calcul distribué utilisées par Megatron-LM peuvent entraîner des frais généraux et des coûts de communications supplémentaires, ce qui peut affecter le temps et l’efficacité de la formation.
Quelques mois plus tard, Hugging Face a développé un modèle appelé DistilBERT (Aurélien et al., 2019). DistilBERT est une version allégée du modèle BERT. Il a été conçu pour fournir une alternative plus efficace et plus rapide à BERT, tout en conservant un haut niveau de performance sur une variété de tâches de TAL. Le modèle est capable de réduire la taille des modèles de 40 % et d’accélérer les temps d’inférence de 60 % par rapport à BERT, sans sacrifier la précision de ses performances. DistillBERT peut donner de bons résultats dans des tâches telles que l’analyse des sentiments, la réponse aux questions et la reconnaissance des entités nommées. Cependant, DistillBERT n’est pas aussi performant que BERT dans certaines tâches de NLP. En outre, il a été pré-entraîné sur un ensemble de données plus petit que BERT, ce qui limite sa capacité à transférer ses connaissances à de nouvelles tâches et à de nouveaux domaines.
Simultanément, Facebook AI a lancé BART (Denoising Autoencoder for Regularizing Translation) en juin 2019. BART (Lewis et al., 2019) est un modèle pré-entraîné de séquence à séquence (Seq2Seq) pour la génération, la traduction et la compréhension du langage naturel. BART est un auto encodeur de débruitage qui utilise une combinaison d’objectifs de débruitage dans le pré-entraînement. Les objectifs de débruitage aident le modèle à apprendre des représentations robustes. BART présente des limites pour la traduction multilingue, ses performances peuvent être sensibles au choix des hyperparamètres, et trouver les hyperparamètres optimaux peut s’avérer difficile. Par ailleurs, l’autoencodeur de BART présente des limites, telles que le manque de capacité à modéliser les dépendances à long terme entre les variables d’entrée et de sortie.
Enfin, nous avons analysé le modèle T5 (Transfer Learning with a Unified Text-to-Text Transformer), introduit par Google AI. T5 (Raffel et al., 2020) est un modèle basé sur un transformateur de séquence à séquence. Il utilise l’objectif MSP (Masked Span Prediction) dans le pré-entraînement, qui consiste à masquer aléatoirement des portions de texte de longueur arbitraire. Par la suite, le modèle prédit les espaces masqués. Bien que le T5 ait obtenu des résultats conformes à l’état de l’art, il est conçu pour être un modèle texte-à-texte polyvalent, ce qui peut parfois donner lieu à des prédictions qui ne sont pas directement pertinentes pour une tâche spécifique ou qui ne se présentent pas dans le format souhaité. En outre, le T5 est un modèle de grande taille, qui nécessite une utilisation importante de la mémoire et prend parfois beaucoup de temps pour l’inférence.
Dans cet article, nous avons abordé les avantages et les inconvénients des dix LLM révolutionnaires qui ont émergé au cours des cinq dernières années. Nous avons également approfondi les architectures sur lesquelles ces modèles ont été construits, en mettant en évidence les contributions significatives qu’ils ont apportées à l’avancement du domaine du NLP.
Novelis a développé un connecteur ChatGPT pour SS&C Blue Prism

Avec l’avancée rapide de la technologie, les entreprises cherchent constamment à rationaliser leurs processus et à minimiser les ressources et le temps nécessaires pour les tâches répétitives. L’automatisation des processus robotiques (RPA) est devenue une solution populaire pour aider à atteindre ces objectifs, et Novelis, une entreprise leader dans l’intégration de systèmes, a développé un connecteur ChatGPT qui améliore considérablement les capacités des logiciels RPA, en particulier SS&C Blue Prism.
Comment le connecteur ChatGPT améliore-t-il SS&C Blue Prism ?
Le connecteur ChatGPT, une technologie de pointe développée par Novelis, offre à SS&C Blue Prism la possibilité d’interagir avec ChatGPT et d’utiliser ses capacités avancées de traitement du langage naturel. Avec cette intégration, SS&C Blue Prism peut automatiser des processus plus complexes qui nécessitent des interactions basées sur le langage, telles que le service client ou l’analyse de données. En exploitant la puissance de ChatGPT, SS&C Blue Prism peut fournir des réponses plus rapides et plus précises aux demandes des clients, ce qui entraîne une plus grande satisfaction des clients et de meilleurs résultats commerciaux. Cette solution innovante permet à SS&C Blue Prism de rester à la pointe dans le paysage en évolution rapide de la technologie d’automatisation.
Use Cases et Usages
Il existe de nombreux use cases pour le connecteur ChatGPT dans SS&C Blue Prism, notamment :
- Service client : Avec le connecteur ChatGPT, SS&C Blue Prism peut automatiser les interactions de service client en comprenant le langage naturel et en répondant de manière appropriée. Cela peut réduire considérablement la charge de travail des agents de service client, leur permettant de se concentrer sur des demandes plus complexes.
- Analyse de données : ChatGPT peut analyser des données non structurées telles que les commentaires des clients, les publications sur les réseaux sociaux ou les avis, et fournir des informations qui peuvent être utilisées pour améliorer les processus métier. SS&C Blue Prism peut utiliser le connecteur ChatGPT pour automatiser l’analyse de ces données, fournissant des informations précieuses en temps réel.
- Automatisation des flux de travail : Blue Prism peut utiliser le connecteur ChatGPT pour automatiser des flux de travail complexes qui nécessitent des interactions basées sur le langage, telles que le traitement de documents ou la gestion de contrats. Cela peut réduire considérablement le temps et les ressources nécessaires pour ces processus, améliorant ainsi l’efficacité et la productivité.
Le connecteur ChatGPT développé par Novelis est un outil précieux pour les entreprises qui utilisent SS&C Blue Prism pour automatiser leurs processus. En donnant à SS&C Blue Prism un accès aux capacités avancées de traitement du langage naturel, les entreprises peuvent rationaliser leurs flux de travail et améliorer leur efficacité. Que ce soit pour automatiser les interactions de service client, analyser des données non structurées ou rationaliser des flux de travail complexes, le connecteur ChatGPT est un outil puissant pour les entreprises cherchant à accroître l’automatisation et à réduire la charge de travail.
À propos de SS&C Blue Prism
SS&C Blue Prism est le leader mondial de l’automatisation intelligente pour les entreprises, transformant la manière dont le travail est effectué. SS&C Blue Prism compte des utilisateurs dans plus de 170 pays et plus de 1 800 entreprises, y compris des entreprises du Fortune 500 et des organisations du secteur public, qui créent de la valeur grâce à de nouvelles façons de travailler, déverrouillant des efficacités et retournant des millions d’heures de travail dans leurs entreprises. Leur force de travail numérique intelligente est intelligente, sécurisée, évolutive et accessible à tous ; libérant les humains pour réinventer le travail.
À propos de ChatGPT
ChatGPT est un modèle de langage développé par OpenAI. L’objectif est de fournir une assistance de qualité en répondant aux questions et en générant des réponses semblables à celles des humains pour faciliter la communication et l’échange d’informations. ChatGPT a été formé sur un vaste corpus de données textuelles et a la capacité de comprendre et de répondre à un large éventail de sujets et de sujets.
